

An update on the central role of distributed computing in modern AI.
By Ben Lorica and Kenn So.
In our previous post we introduced a class of AI startups (“pegacorns”) that have at least $100 million in annual revenue. Many of the AI pegacorns sell applications rather than infrastructure, and many of their founders cited proficiency in technologies like cloud computing and distributed systems.

Cloud computing is an obvious skill for a technical founder, but what about distributed computing? Invoking independent components that are installed on different systems and communicate with one another in order to achieve a shared objective, has long been critical to building large-scale data and machine learning applications. Today, there are a number of distributed computing tools and frameworks that do most of the heavy lifting for developers. Solutions like Apache Spark, Apache Kafka, Ray, and several distributed data management systems have become standard in modern data and machine learning platforms.
Even as specialized hardware for building AI applications continues to improve, UC Berkeley Professor Ion Stoica and others have noted that future trends point to the need for distributed computing for AI. Training and serving machine learning models at scale requires tremendous amounts of compute resources. For example, Facebook serves trillions of predictions daily and the number keeps growing.
Future trends point to the need for distributed computing for AI
There have long been tools for distributed training (e.g. Spark ML and MLlib) but in recent years the need for distributed computing tools and skills has intensified with the growing importance of large neural network models. Anthrophic’s Jack Clark recently observed: “One of the really big challenges we have is running really large clusters, capable of doing machine learning jobs on hundreds of thousands of GPUs.” And while new tools to simplify distributed training and inference continue to emerge – Ray Train, Ray Serve, and Google Pathways – most solutions still require people skilled at running and managing large-scale distributed systems.
In this post, we’ll examine metrics that measure interest in distributed systems and distributed computing with an eye towards their implications for machine learning and AI.
Distributed Computing and the Research Community
A natural place to start is to examine interest within the research community. From 2017 to 2021 the number of papers on the popular preprint server arXiv grew over 220%. Papers that mention “distributed computing “/ “distributed systems” (DCS) kept pace and accounted for more than 3% of all papers each year spanning 2017-2021.

There have been over 3,500 DCS preprints on arXiv since 2020, but to what extent do those papers cover machine learning and AI? We use Zeta Alpha’s built-in visualization tool (VOSviewer) to display bibliometric networks1 within the corpus of DCS papers from 2020 to the present. As we highlight in Figure 3 below, there are clusters of papers heavily focused on machine learning and deep learning topics:

Distributed Computing in Industry
To measure industry interest, we first look at the demand side of the labor market through the lens of job postings in a few key U.S. metropolitan areas. With the exception of data science jobs, which have almost tripled over the past year, “distributed computing” job postings have grown at about the same rate as other AI-related topics. We examine key roles that require “distributed computing” skills. Aside from technical roles normally associated with distributed systems (software engineer; developer), we found that among the top job roles were those associated with artificial intelligence (data science; machine learning / deep learning).

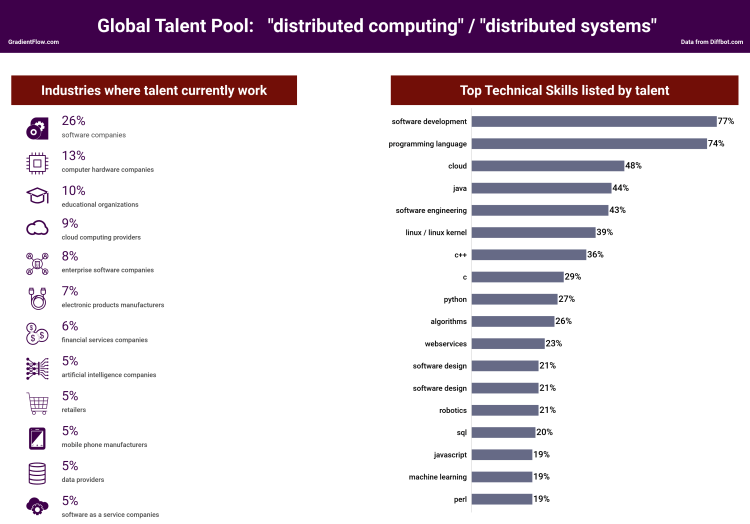
The supply-side of the labor market is extensive: according to Diffbot2 there are over 200,000 people who list “distributed computing” and/or “distributed systems” on their profiles. The global DCS talent pool has representatives from over 50 countries, including over 50,000 in the U.S. Based on the graphic below, the global DCS talent pool favors programming languages like Java/C++/C over Python. There is an explicit link with AI: about one in five list machine learning (19%) and robotics (21%) on their profiles.
Patent filings are another way to gauge industry interest. The number of DCS patents grew 36% from 2018 to 2019, and the number has hovered around 700 annually since 2019. The number of patents published in China has exploded and China now rivals the U.S. for the number of DCS patents.

In the next graphic we display key phrases from the over 2,400 DCS patents that have been published since 2019. Many phrases that we surface are familiar to data engineers and data scientists who work with popular distributed systems like Apache Spark. We highlight a few prevalent phrases that are explicitly related to machine learning and AI:


Bringing distributed computing to data scientists
Now that we’ve described the state of distributed computing in AI at the macro level, let’s shift gears to look into how this affects data scientists. What we’ve seen is the translation of academic research & industry demand into tools that fit the data scientist workflow – which revolves around notebooks written in Python. We’re beginning to see tools like Modin (distributed Pandas library) that seamlessly scale popular data science tools and APIs.
Job postings, the global talent pool and patent filings for distributed computing have subgroups that overlap with machine learning and AI
We present the major stages in a machine learning pipeline and a sampling of companies, frameworks, and list solutions that address distributed computing needs of data scientists at each stage:
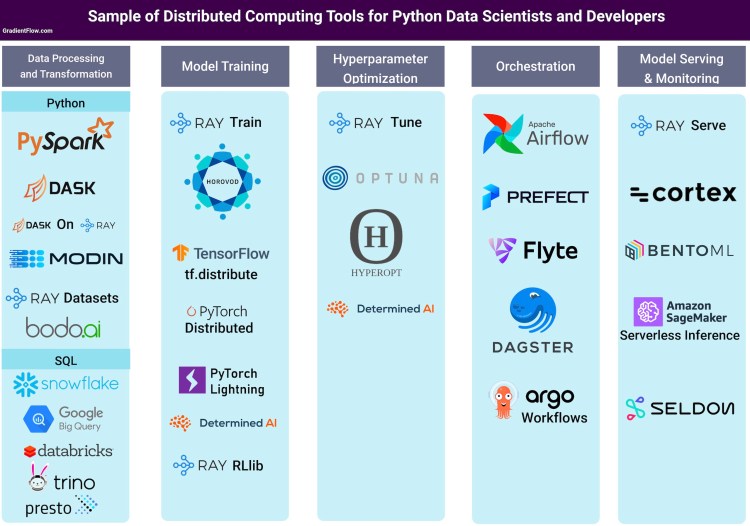
We conclude by highlighting a few trends to watch out for in the years to come.
- Foundation Models decreases then increases demand: At least for areas where foundation models (e.g., large language models) are available, large-scale training will be less common. Foundation models enable teams to start with pretrained models and embeddings, rather than train models from scratch. But foundation models make it easier for entrepreneurs to build new applications, eventually increasing the demand for distributed computing to power those applications (for model serving, orchestration and data processing).
- New applications for distributed computing: As new techniques like reinforcement learning, graph neural networks, and end-to-end multimodal models get deployed in real-world applications, we expect new libraries aimed at making these techniques accessible to practitioners. Demand for distributed computing solutions will increase alongside these new modeling methodologies.
- Consolidation of window panes: It’s too difficult for many teams to piece together multiple distributed computing frameworks. We predict that most teams will either gravitate towards platforms like Databricks, or build their own platforms using components that are tightly integrated (Ray AI Runtime; or managed services from major cloud providers).
- Ease of use and infinite laptops: Figure 9 lists solutions that democratize distributed computing. Many of these tools allow data scientists to scale using familiar tools or using simple APIs. The next generation of tools will go a step further. Data scientists will be able to develop ML models on their laptops using familiar tools and libraries, and scale seamlessly to a heterogeneous cluster as needed.
- Front-end as the next frontier for data scientists: As the back end pain of distributed computing eases and more pre-built libraries make it easier for data scientists to build their models, the next step is to make it easier to communicate and distribute their work. Data app frameworks like Streamlit (which Snowflake bought for $800 million) enable data scientists to become “full-stack”. Another example is Hex, a platform that allows data scientists to build and deploy full stack data apps.
Summary
Distributed computing is a skill cited by founders of many AI pegacorns. To demonstrate the overlap between distributed computing and AI, we drew on several data sources. We found that job postings, the global talent pool and patent filings for distributed computing all had subgroups that overlap with machine learning and AI. We close by listing a few trends that will impact the future role of distributed computing in AI.
Related Content:
- Pegacorns: The AI $100M Revenue Club
- Resurgence of Conversational AI
- Data Quality Unpacked
- What is Graph Intelligence?
- The Data Exchange podcast: Large Language Models
- Most State-Of-The-Art AI Systems Are Trained With Extra Data
Kenn So is an investor at Shasta Ventures, an early-stage VC, and was previously a data scientist. Opinions expressed here are solely his own.
Ben Lorica helps organize the Data+AI Summit and the Ray Summit, is co-chair of the NLP Summit, and principal at Gradient Flow. He is an advisor to Databricks, Anyscale and other startups.
Subscribe to the Gradient Flow Newsletter:
[1] Bibliometric networks are citation, co-citation, bibliographic coupling, keyword co-occurrence, and coauthorship networks.
[2] In Diffbot’s knowledge graph, a company can be tagged as belonging to multiple industries.