



Choosing the Right Vector Search System
By Ben Lorica and Prashanth Rao.
Since we released a vector database index nearly two years ago, the landscape of vector search and databases has evolved dramatically. The rise of Retrieval-Augmented Generation (RAG) has been a pivotal factor, with embeddings emerging as the lingua franca of Generative AI. This paradigm shift has spurred a surge in new systems, with the emergence of numerous vector search and database startups. Additionally, established data management platforms like Postgres, Databricks, MongoDB, and Neo4j have integrated vector search capabilities into their offerings.
With so many options now available, it’s essential to understand the features that differentiate these systems. As usage increases and the volume of embeddings grows, selecting the right vector search system becomes critical. This article provides a decision guide based on a comprehensive list of features, enabling teams to tailor their choices to their specific needs and priorities.


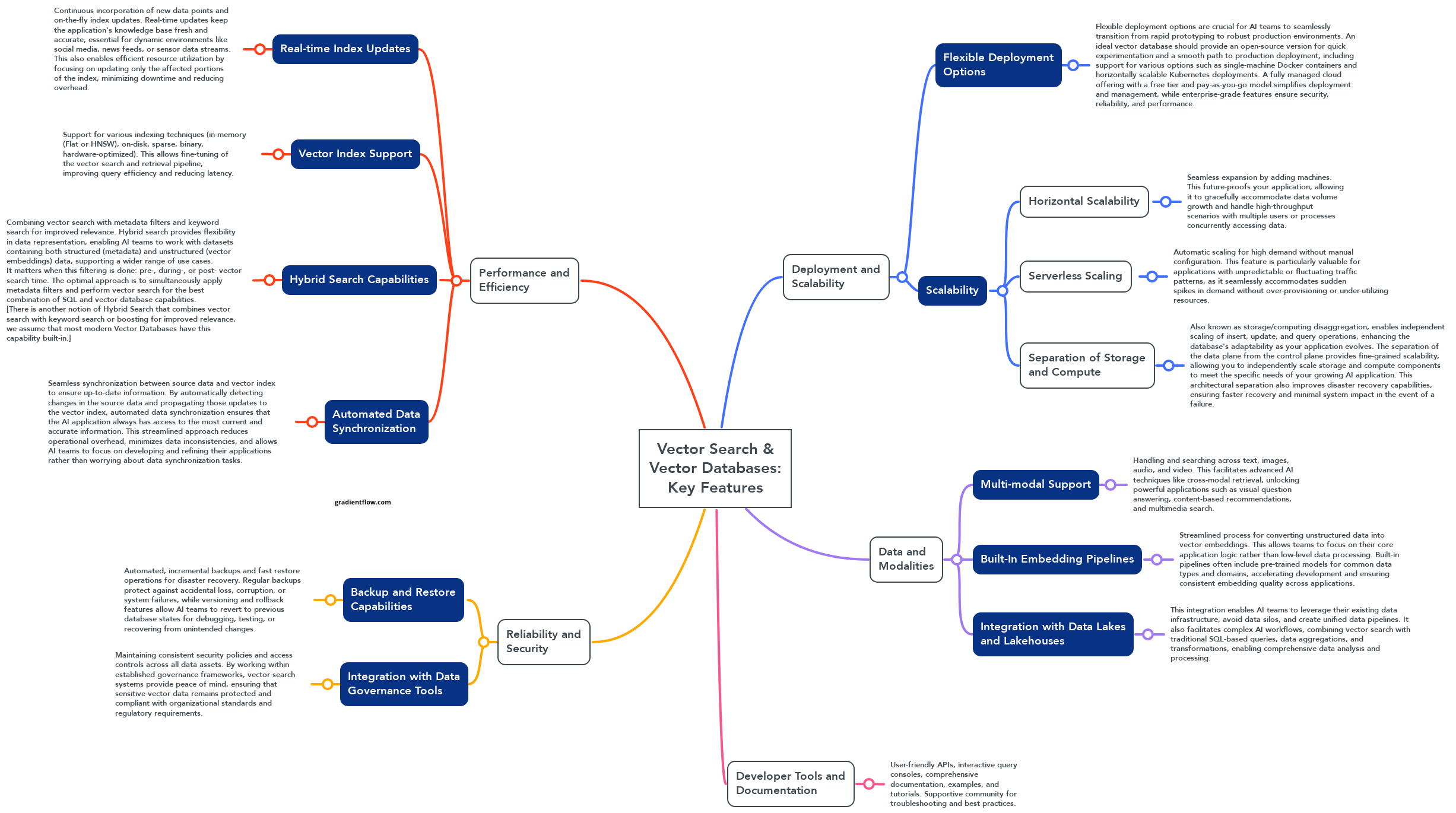
Deployment and Scalability
Scalability is paramount. The system must adapt to your evolving needs and expanding use cases, allowing for seamless transitions from rapid prototyping to robust production environments. Look for solutions that offer both open-source versions for quick experimentation and enterprise-grade features for production, including single-machine Docker containers and horizontally scalable Kubernetes deployments. Fully managed cloud offerings with pay-as-you-go models can simplify deployment and management, ensuring security, reliability, and performance.
Horizontal scalability is crucial for handling vast amounts of vector data. Systems that expand seamlessly by adding more machines to the cluster without disrupting operations or performance can manage increasing data storage and processing demands effectively. This future-proofs applications, enabling them to accommodate data volume growth and handle high-throughput scenarios with multiple users or processes accessing data concurrently.
The separation of storage and compute enhances scalability and cost-effectiveness. By allowing independent scaling of insert, update, and query operations, this architecture provides fine-grained control, enabling applications to evolve without being constrained by infrastructure limitations, while also allowing users to pay only for the compute and storage they need. This separation also improves disaster recovery, ensuring faster recovery times and minimal system impact in the event of failures.

Performance and Efficiency
For AI applications operating in dynamic environments, real-time index updates are essential. This feature allows databases to continuously incorporate new data points and update the index on-the-fly, ensuring access to the most relevant information. Applications like social media, news feeds, or sensor data streams, where fresh and accurate information is crucial, rely heavily on this capability.
Furthermore, robust vector index support is critical for performance optimization. Systems that offer a variety of indexing techniques, such as in-memory indexes like HNSW for rapid querying, or on-disk indexes for larger datasets, allow for efficient query processing and fast delivery of results. This flexibility enables fine-tuning the vector search pipeline, optimizing query efficiency and reducing latency.
Hybrid search capabilities, combining vector search with keyword-based search and metadata filtering, significantly enhance query relevance and performance. By narrowing the search space, these systems deliver more precise and relevant results, broadening the scope of potential use cases. This simultaneous application of metadata filters, keyword-based search (using methods like BM25 or SPLADE) and vector search effectively leverages both structured and unstructured data, ensuring optimal performance.
Data, Reliability, and Security
For seamless integration and efficient workflows, vector search systems should offer built-in embedding pipelines [1, 2] and seamless integration with existing data governance tools. Built-in embedding pipelines streamline the process of converting unstructured data into vector embeddings, automating tasks like data preparation, model selection, and transformation. This abstraction of complexities allows AI teams to focus on core application logic rather than low-level data processing, accelerating development and deployment.


Integration with data governance tools is crucial for maintaining consistent security policies and access controls across all data assets, including vector databases. Solutions that leverage existing security measures and governance frameworks reduce management complexity and ensure compliance with organizational standards and regulatory requirements. By leveraging the same security measures and governance tools already in place for lakehouses, vector search systems eliminate the need to create and maintain separate data governance policies specifically for unstructured vector data, providing peace of mind knowing that sensitive vector data remains protected and compliant.


Analysis
- To effectively choose a vector search system, prioritize the features discussed in this guide based on your specific use cases, recognizing that each feature addresses distinct aspects of vector search and database functionality.
- Start with building a proof-of-concept using an easily accessible vector search system that meets your application’s needs. There are many open source systems to choose from that are easy to start with and provide features for developer productivity. Open source systems are typically a good starting point.
- It’s wise to choose tools that can scale with your project’s requirements. Not all vector search systems are open-source, so spend some time studying your use case (including data and query throughput) to understand whether your chosen solution meets your application’s needs. Develop custom monitoring solutions to track your application’s usage if required.
- Spend adequate time preparing an evaluation dataset so that you can verify that your solution is meeting its design goals in terms of performance (recall and latency) as well as cost. It may be necessary to create a small human annotated dataset (~100 samples) for your domain and quantify the system’s performance in order to convince business leaders that it improves on prior solutions for the same task.
- Begin with simpler methods like rule-based or keyword search-based methods to establish a baseline, and then compare the baseline results with more advanced methods like hybrid search and reranking to convince yourself that the solution that’s based on vector search is indeed performing better across a wide range of samples.
- It seems easier for traditional or incumbent database management systems (DBMSs) to incorporate vector search than it is for dedicated vector database startups to add full DBMS features. This is even more true from a business sense, i.e., organizations are happy to stick with incumbent DBMSs rather than switch to a new system, despite any added technical benefits of the dedicated vector search system.
- To remain relevant over time, a lot of vector database startups will have to offer many more features for advanced management and governance of embeddings, indexing and multimodal data to meet the evolving needs of AI teams.
- Monitor emerging open source data and file formats – these will play a pivotal role in upcoming search and retrieval systems by enhancing interoperability and data management practices. Make sure to choose a vector search solution that plays well with these popular file formats and offers developer-friendly features from a data engineering perspective.
- It’s clear that vector search will continue to empower a host of new AI applications. There are a lot of vector search solutions available in the market today, but because many of them offer similar features from a vector search perspective, it’s unlikely that any one vendor will become dominant over the others. Don’t spend much time looking for the “perfect” system – the right tool for your application is one that meets latency, cost and accuracy requirements while balancing the tradeoffs involved.


Data Exchange Podcast
1. Fine-tuning and Preference Alignment in a Single Streamlined Process. Jiwoo Hong and Noah Lee from KAIST AI discuss their novel method, ORPO (Odds Ratio Preference Optimization), which efficiently aligns language models with human preferences using significantly smaller datasets compared to traditional methods like RLHF and DPO.
2. TinyML, Sensor-Driven AI, and Advances in Large Language Models. Pete Warden introduces Useful Sensors, a company developing AI solutions for consumer electronics and appliances, and discusses the concept of TinyML and its evolution towards sensor-driven AI. The conversation covers recent advances in large language models, product development considerations, and the importance of privacy, security, and third-party verification in AI systems.


Lessons from the ‘Noisy Factors’ Study
My first job after academia was in quantitative finance, a field that relies heavily on the use of mathematical models and statistical methods to analyze financial markets. One of the most widely used tools in this field is the Fama-French factors, a set of variables developed by Nobel laureate Eugene Fama and Kenneth French to explain stock returns. These factors include market risk, company size, and value vs. growth characteristics, and they are crucial for understanding stock market behavior, evaluating investments, and estimating the cost of capital. However, a recent study titled “Noisy Factors” uncovered significant inconsistencies in the Fama-French factor data, revealing that the factor values varied depending on the download time.
The findings cast doubt on the reliability of financial research, investment valuations, cost of capital estimations, and even legal arguments based on these factors. For example, changes in the Fama-French factors over time can dramatically affect performance metrics, such as alpha and beta, which are used to evaluate investment strategies. Additionally, businesses rely on these factors to calculate their cost of capital, which is essential for making investment decisions. Inconsistencies in the factors can lead to incorrect cost of capital estimates, potentially affecting a company’s financial planning and decision-making. The study emphasizes the need for transparent and reproducible financial data to maintain confidence in research and investment strategies.


This brings us to a broader lesson for AI enthusiasts: the critical importance of data quality and transparency. Just as inconsistencies in the Fama-French factors can lead to unreliable results in finance, inconsistent or noisy data can lead to unreliable results in AI. This emphasizes the need for regular audits and version control of datasets used in AI research and development. Transparency in data collection, preprocessing, and model training processes enhances the credibility and reproducibility of AI models.
Reproducibility is essential in scientific research, and AI practitioners should prioritize sharing code, data, and detailed documentation. This allows other team members to verify results and build upon existing work. Methodological changes in AI models can significantly impact performance, necessitating thorough documentation and justification. Relying on single-source datasets or proprietary tools without understanding their limitations is risky, and diversifying data sources while ensuring documentation can mitigate this risk.


The “Data-centric AI” community focuses on improving the quality, quantity, and diversity of data used to train AI models, recognizing that data plays a crucial role in the performance and reliability of AI systems. This community advocates for investing more resources in data collection, cleaning, and annotation, rather than solely focusing on improving algorithms. The rise of new tools like fastdup, a powerful free tool designed to rapidly extract valuable insights from image and video datasets, is a testament to this focus. These tools assist in increasing dataset quality and reducing data operations costs at an unparalleled scale.
Ensuring data integrity and transparency is not just a best practice but a necessity for building robust, reliable AI applications. By learning from the “Noisy Factors” saga, we can better navigate the complexities of data-driven application development.
Recent Articles
- SB 1047 Unpacked
- Mamba-2 and State Space Models
- AI at WWDC 2024
- The Promise and Perils of AI Avatars in the Workplace
- Reducing AI Hallucinations: Lessons from Legal AI
If you enjoyed this post please support our work by encouraging your friends and colleagues to subscribe to our newsletter:

{kind=link}
{kind=link}
{kind=link}
{kind=link}