

Companies have a pressing need for good data
By Kenn So and Ben Lorica.
As much as we loathe to repeat what has been written hundreds of times, we have to: the world is data driven. Companies gather more data about their customers to build better products, and those who can make use of that data are at a competitive advantage. The challenge is that the data stack is becoming increasingly more complicated. Considerations today go beyond the variety, volume, and velocity of data.
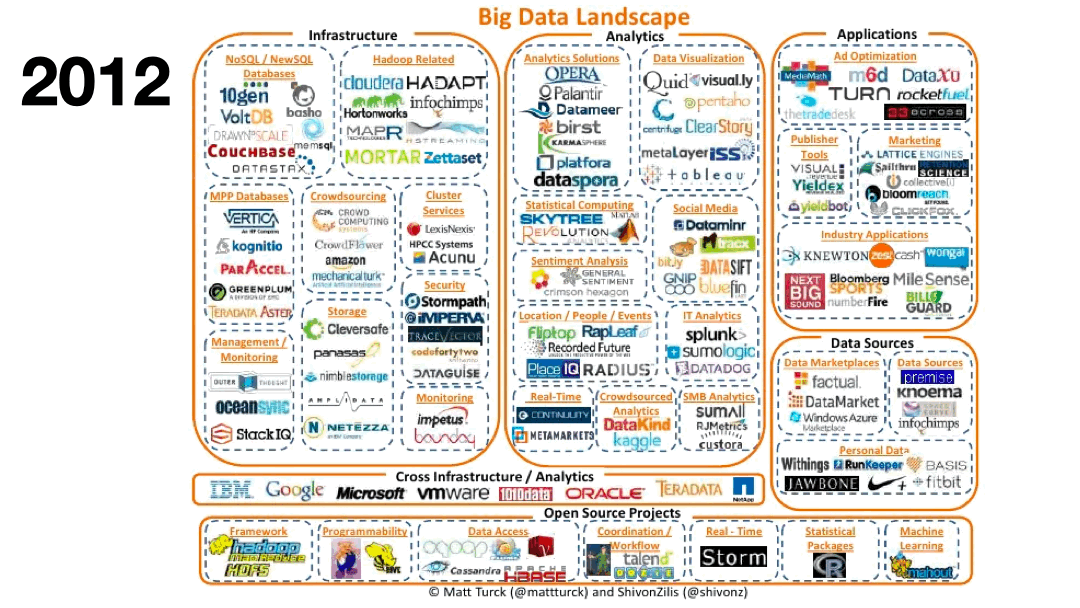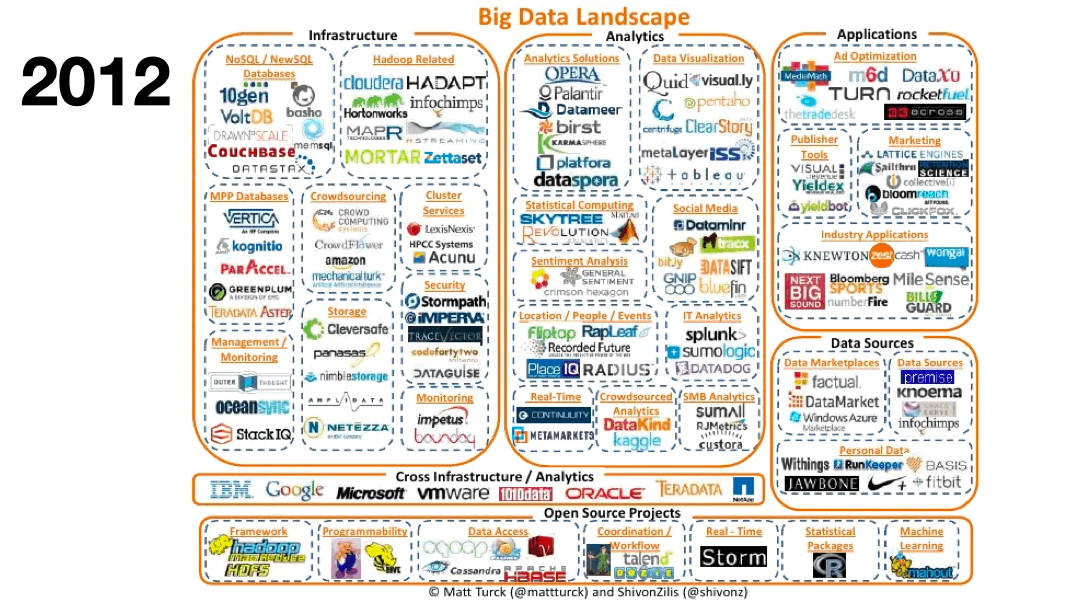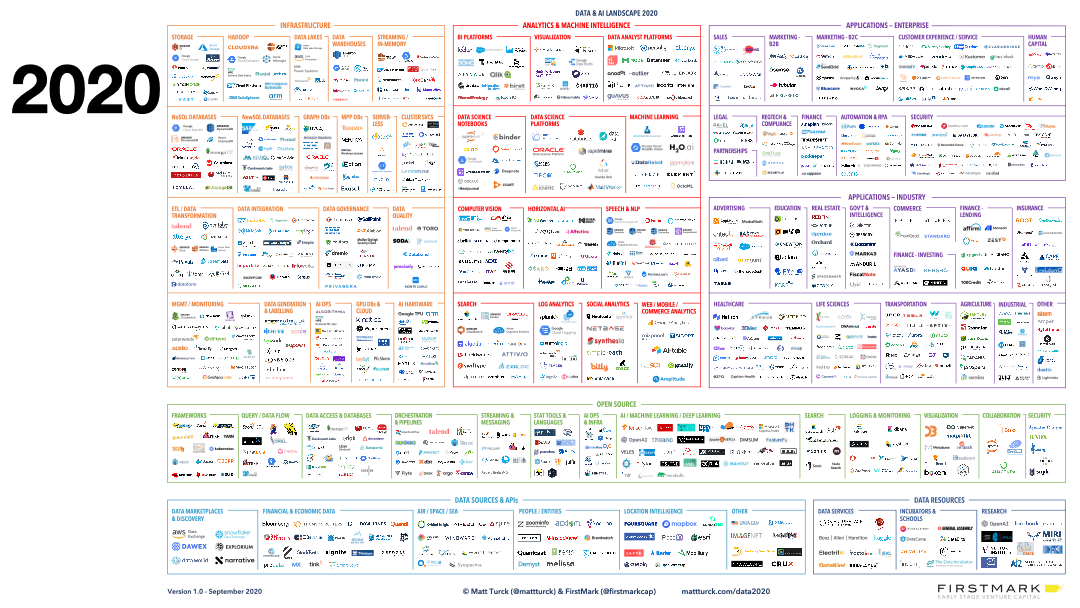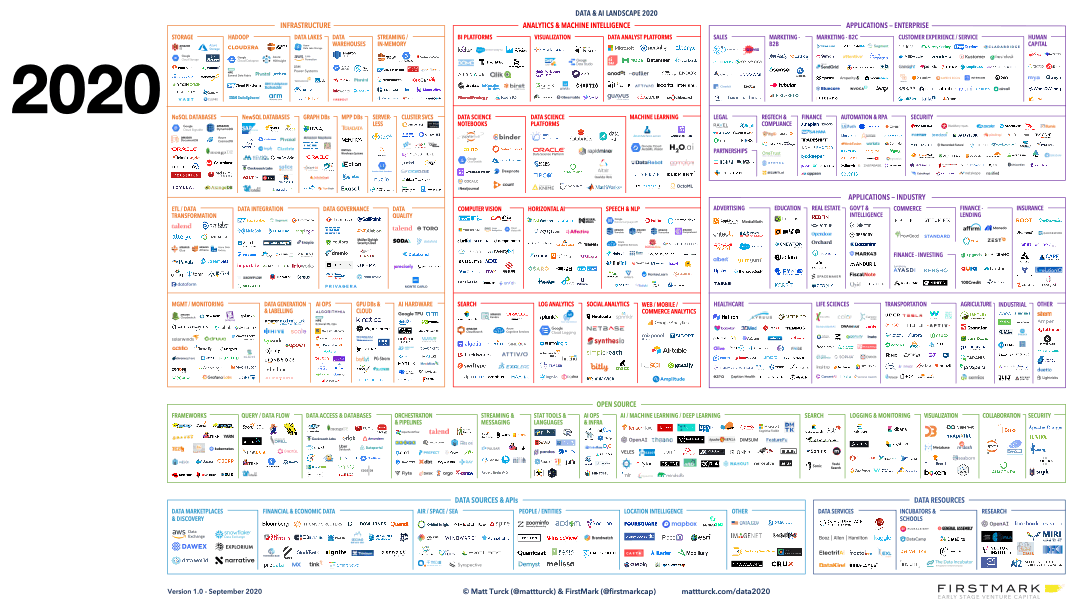
What has changed over the past decade is that most of our daily interactions are directed by machine learning and analytic models processing thousands to millions of data points in real time. Most business decisions today rely on data: spam filters and autocomplete for emails, recommendations for online shopping, biometrics categorization for sleep tracking, route optimization for daily drives, to name a few. Supporting all of these applications and data products requires robust data technology stacks.
To remain competitive, companies are making data quality a top priority. After all, the benefits of data quality are clear. For example, let’s consider data quality in the context of machine learning and AI. In a recent survey, McKinsey found that with AI/ML adoption, 66% of companies have increased their revenues and 40% have decreased costs. And good AI/ML is fully dependent on good underlying data.
Andrew Ng recently presented a widely-shared talk where he surveyed studies showing how improving data significantly improves model accuracy, while improving the model algorithm had little to no effect.

The rapid development of COVID models last year to help public and health professionals to deal with the crisis provides a good example of the importance of data quality. Multiple reviews showed that the models were largely useless because of bad data (see MIT Technology Review). Issues included formats that were not standardized, duplications and mislabeled data, and so on.
More broadly, on the business side, the estimated cost of bad data is $15 million annually for each organization (see Gartner). This is not a new concern. Enterprises have already been spending $208,000 annually for on-premise data quality solutions (see Gartner). Yet, bad data continues to be a growing concern that is getting more difficult with the introduction of more data sources and data types. This is why we are seeing an emerging crop of data quality startups funded by top-tier venture capitalists, including Monte Carlo, Great Expectations, BigEye, Soda, OwlDQ (now part of Collibra). We are also seeing large startups like Databricks and Scale build data quality features into their product suite.
Data Quality Solutions Are Essential
The growing importance of analytics and machine learning applications demands modern data quality solutions. Figure 3 illustrates the increasing complexity of data pipelines and development processes.

Data Quality Roles
Data quality is important, but whose job is it? An examination of US job postings in select regional areas reveals that the responsibility for data quality is spread across a variety of roles, from analytics managers to data scientists to software architects.


Figure 4: An examination of US job postings in select regional areas reveals that the responsibility for data quality is spread across a variety of roles, from analytics managers to data scientists to software architects. Charts: Gradient Flow.
If OpenAI’s activities hint at future trends, then this recent job posting for a full-time data quality engineer is telling. Data quality-focused roles—for example, a data quality assurance specialist—tend to involve human reviewers manually checking data. This requires the specialist to manually write and rewrite tests and rules. This is an important role, but it is not scalable. We expect that, in the near future, data organizations will have a dedicated person or team scaling data quality alongside specialized and automated tools.

Data Quality as a Concept
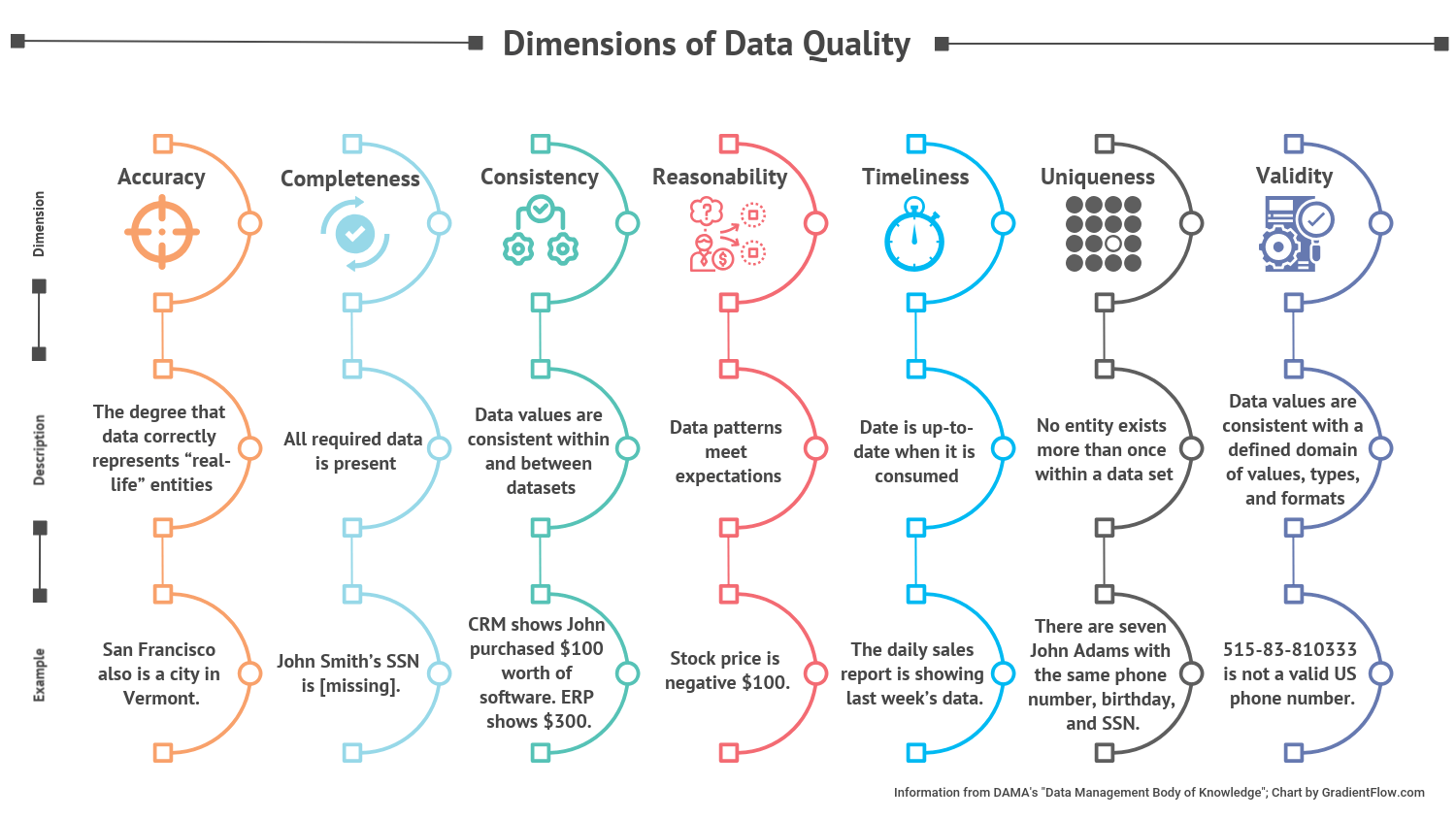
As a concept, data is high quality if it meets the users’ specific needs. For example, accounting data is high quality if it is accurate and comprehensive. Machine learning data is high quality if it is representative of the underlying population and scenarios. While good quality differs from case to case, there are common dimensions of data quality that can be measured. DAMA, a global professional data community, synthesized data quality dimensions in their book Data Management Body of Knowledge. Their assessment is illustrated in Figure 6.
Data Quality Solutions
Now that we know what data quality is as a concept, what should be included in a solution? Instead of listing a set of features (e.g., address validation, deduplication), where some are table stakes, we list broad capabilities that should be included in all modern data quality solutions:
-
-
Data profiling is the process of understanding the data. Tools should have the ability to summarize key metadata about datasets, such as size, row/column count, source, recency, missing values, etc. This serves as the foundation of all other capabilities. Data professionals should be able to understand what a dataset is about in one view.
-
-
-
Data quality measurements are summary statistics indicating data quality. This is often calculated indirectly as a proportion of data quality violations—missing values, for example—in a dataset. The difficult part of data quality measurement is building custom metrics and rules to address the data quality dimensions listed in Figure 6, in addition to quality metrics. Data professionals should be able to define what healthy data looks like and know at any point the health of all datasets.
-
-
-
Data cleansing and repair: data quality issues are inevitable. Tools should help diagnose root causes of errors and, if practical, automatically repair errors. Some corrections, like deduplication, can be automated while others have to be manually fixed—for example, a broken API link. Data professionals should be able to triage and resolve data errors easily.
-
-
-
Great UX: a user-friendly interface is essential for both technical and non-technical professionals to interact with any tool. For data professionals and developers, this can mean the difference between writing custom scripts or having access to built-in tools to streamline end-to-end data quality tests and monitoring. For domain experts who are non-developers, this means being able to easily contribute to improving data quality.
-
Advanced capabilities for specific use cases: for example, real-time entity resolution (see Senzing), metadata management, and support for specific data formats and types.
-
New Data Quality Vendors
In this section, we list a representative sample of modern data quality solutions offered by startups. There are other lists of established vendors, but the recent wave of venture funding into the space signals that modern data quality solutions are needed to fit the modern data landscape.

Summary
Data quality is an active area of business and innovation. On the demand side, we see companies including data quality in job postings; on the supply side, there are many new startups offering data quality solutions. We listed several reasons why data quality has become a requirement for companies as data sources and types continue to grow, and data stacks are becoming more complex.
In this post, we discussed what data quality is and outlined key features of modern data quality solutions. Looking to the future, data quality solutions and processes will increasingly be required before any data product or service is deployed. Along these lines, there’s been a recent wave of startups tackling structured data. But we have not yet seen such a wave for unstructured data (e.g., text) which has a larger footprint than structured data and is powering more novel applications. This is where we’ll see the next wave of data quality startups.
Kenn So is an investor at Shasta Ventures, an early-stage VC, and was previously a data scientist. Opinions expressed here are solely his own. Shasta Ventures is an investor in ActiveLoop and Hasty.
Ben Lorica is co-chair of the Ray Summit, chair of the NLP Summit, and principal at Gradient Flow. He is an advisor to Databricks.
Related Content: