

How Teams Actually Use RL to Make Agents Reliable
I have had a longstanding fascination with reinforcement learning (RL) and have monitored its slow diffusion from research labs into enterprise production. Much of the recent activity remains concentrated among foundation model builders and teams with dedicated post-training capacity. They use RL after pre-training to make large models reliable at executing tasks, not just generating text. This includes training agents to operate business software like CRMs and ticketing systems, run commands in cloud terminals, extract structured fields from messy documents, and navigate realistic user interfaces. In a few frontier cases, RL is even driving closed-loop workflows where a model proposes an action, tests it in a simulator, and learns from the measured outcomes.
To better understand real-world demand, I recently examined job postings in key U.S. technology hubs that mentioned RL. The results show that adoption is broader than just research labs. As the chart below illustrates, RL appears most often alongside Generative AI (57%) and AI infrastructure (43%), followed closely by autonomous agents (23%). There is also a long tail of activity across search, robotics, computer vision, and predictive analytics. The chart below provides a clear view of these diverse application areas.

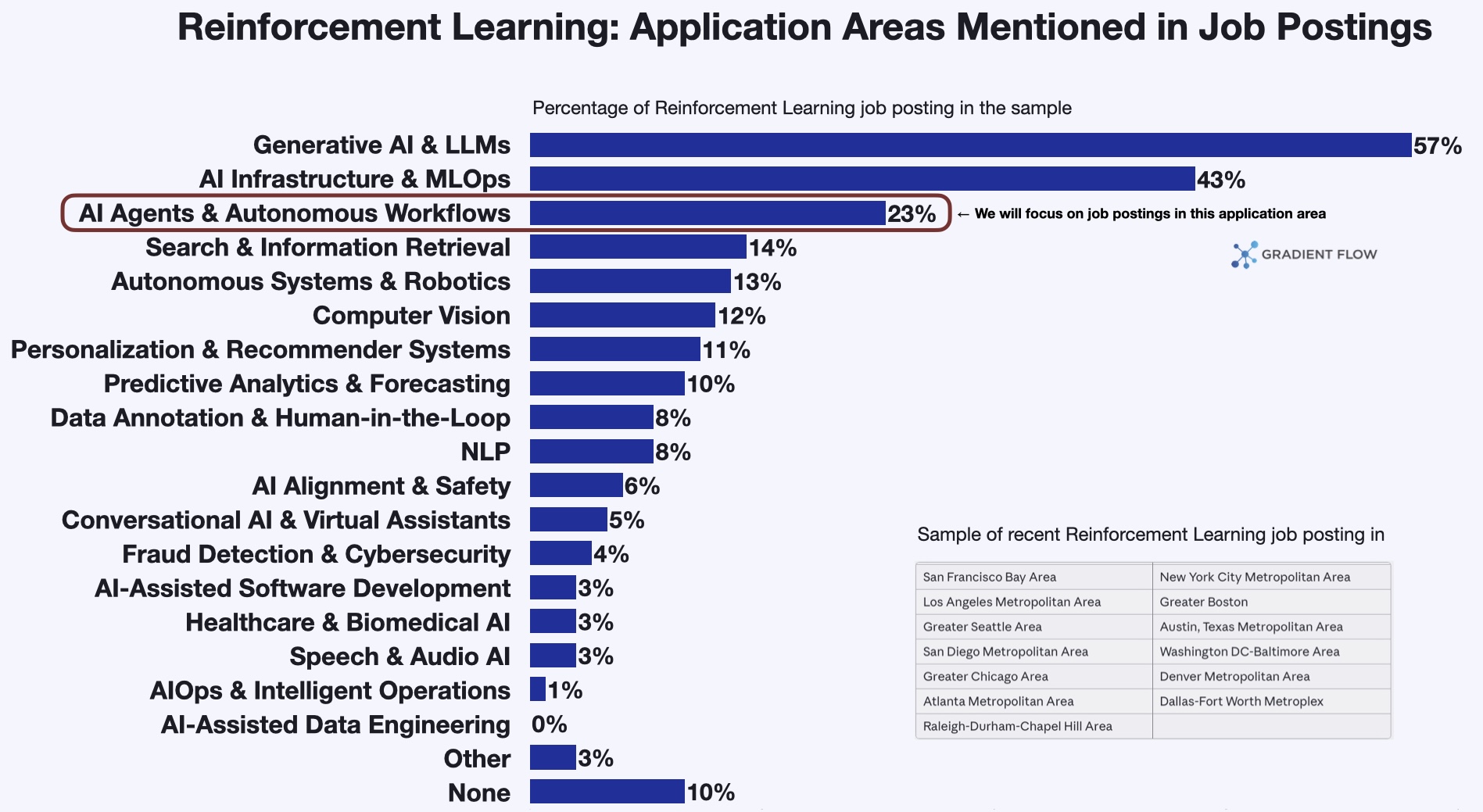{kind=link}
While the data spans a wide spectrum, the most dynamic category is AI Agents & Autonomous Workflows. This sector represents the shift from passive chatbots to active systems that can execute complex tasks. Below is a closer look at how engineering teams are deploying RL to build these agentic systems across eight distinct domains.
Dynamic Revenue Optimization
In high-velocity environments like advertising and digital commerce, agents are replacing static rules with dynamic policies. Developers use contextual bandits to make split-second decisions on ad placement or pricing by learning directly from user clicks and conversions. The complexity lies in managing competing objectives. Through constrained reinforcement learning, these agents maximize revenue while strictly adhering to safety guardrails and budget caps. This approach allows systems to autonomously negotiate B2B transactions or adjust campaign bidding strategies in real time with less manual tuning day to day. In postings, this work is usually framed as bidding and budget policies, constrained optimization, and learning from advertiser or customer feedback when recommendations get accepted, rejected, or modified.
Autonomous Software Refactoring
Beyond simple code completion, agents are taking on deep software engineering tasks like language migration and vulnerability patching. The advantage here is objective feedback: compilers, tests, and deployment checks serve as verifiers. Agents receive negative rewards when code fails to build or pass assertions, creating a tight, iterative learning loop where the model refines its policy for code generation and refactoring until it produces correct solutions. This is especially valuable for long, interdependent workflows where order matters and early mistakes cascade. In job postings, this appears as autonomous debugging, test-driven agents, codebase migration automation, and policies that optimize for passing builds and safe rollouts.

{kind=link}
Beyond Robotic Process Automation
In back-office settings, RL is often used to turn “tool use” into something closer to a dependable habit. Teams train agents on company-specific rules and tone using human feedback, then push further with offline RL that learns from logs of how skilled operators actually resolve cases. The RL signal is usually tied to outcomes practitioners care about, like fewer escalations, fewer retries, and clean completion of a workflow across systems such as HR, IT, finance, and CRM tools. In job postings, this tends to show up as agentic workflow automation, tool calling, human-in-the-loop review, and reward design that handles delayed outcomes.
Automated Red Teaming
Security teams are deploying agents to operate at machine speed for both defense and automated testing. Because security threats develop quickly and visibility is incomplete, agents must make decisions under uncertainty. Red team agents learn attack strategies in simulated environments while blue team agents learn to detect intrusions from incomplete alert data. This adversarial training discovers novel attack strategies and robust defenses that human analysts might miss during manual penetration testing. In job postings, this appears as autonomous incident response, continuous red teaming, adversarial training, and environments that let agents rehearse safely.

Deep Information Synthesis (including Deep Research)
For tasks requiring “System 2” thinking, such as comprehensive market research or legal synthesis, engineers employ process supervision to reward intermediate steps rather than relying solely on final outcomes. This encourages agents to gather evidence, cite sources, and recognize when they need to search further, instead of hallucinating plausible answers. The result is a system that follows verifiable paths while knowing when to keep searching. In job postings, this shows up as process supervision, evidence-based synthesis, citation quality, and workflows that explicitly train agents to avoid shortcuts.
Autonomous Supply Chain Management
Logistics and supply chain applications require agents to bridge the digital and physical worlds. Whether managing warehouse robots or routing delivery fleets, these systems treat operational choices as sequential steps that reshape the network. Routing decisions, for instance, ripple through fleet availability, queue lengths, and delivery windows. Since training on live hardware is prohibitively expensive and dangerous, teams rely on simulation-based training. Agents master complex control tasks before transferring policies to the real world, balancing competing objectives like delivery speed, fuel costs, and safety margins. In job postings, these topics show up around dispatch and routing policies, digital twins, sim-to-real transfer, and constrained control for robotics and autonomous systems.
We are witnessing a shift from passive chatbots to active systems, where RL is used to turn ‘tool use’ into dependable, repeatable habits.
Autonomous Scientific Discovery
In fields like pharmaceuticals and materials science, “scientist agents” close the loop between hypothesis generation and physical experimentation. They use active learning to navigate vast search spaces of potential compounds or materials. Because physical experiments are slow and expensive, teams typically train policies in simulation first and then use real experiments as high-value feedback. The core technical challenge is balancing exploration against exploitation: the agent must decide whether to refine a promising candidate or test a novel hypothesis, optimizing experimental design to maximize information gain while minimizing the time and cost of lab work. In job postings, the work shows up as closed-loop experimentation, lab robotics integration, simulation-driven training, and methods for balancing exploration with exploitation.
RL in the Agent Orchestration Layer
As agent ecosystems grow, infrastructure engineers are building the orchestration layers that manage them. The focus here is on the “agent runtime” where reinforcement learning optimizes how requests are routed to specialist workers. Rather than hard-coding which tool or agent to invoke and in what sequence, the system learns a policy based on success rates and constraints like latency and cost. Teams are also building evaluator agents that score plan quality, creating feedback loops where the orchestration layer continuously refines its coordination strategies based on actual task outcomes. In job postings, this looks like agent routers, planner-executor architectures, multi-agent coordination, evaluation frameworks, and guardrails that can be optimized over time.

These eight domains illustrate where RL appears in production agent systems. RL is one approach among several for improving reliability and decision quality. In previous work, we explored complementary techniques including evolutionary methods for discovering optimal agent architectures and structured observability that turns agent debugging from guesswork into measurable engineering. The common thread across these strategies is identical: moving from costly trial-and-error toward systematic, repeatable improvement.
Simulation First, Production Later: Safe RL Deployment Patterns
Across these domains, the technical patterns are surprisingly consistent. Most teams start with offline RL from production logs, because naive online exploration is risky when the “environment” is a real business process or a live system. From there, the work quickly becomes about constraints and rollouts. Policies are trained in simulation or test environments, they ship behind safety filters, and they graduate from “suggest” to “act with confirmation” to limited autonomy for routine cases. Reward design is rarely a single number: it is usually a bundle of outcome metrics with hard limits on things like budget, latency, and safety.

{kind=link}
The market signal in the postings is not “more RL research.” There is demand for people who can connect RL ideas to production realities: instrumentation, evals that match business outcomes, careful guardrails, and integration with existing systems. If you are building agentic workflows, RL is showing up less as a magic upgrade and more as a way to learn better sequential decisions under real operational constraints.
Quick Take