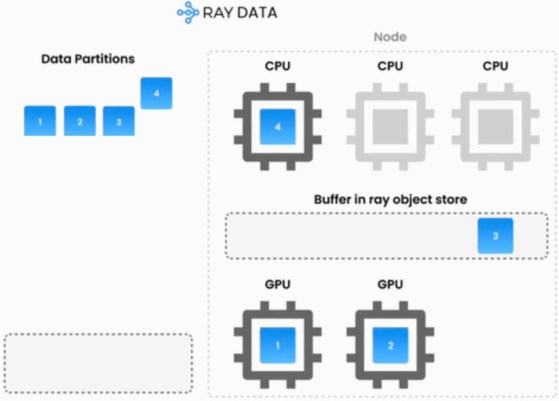
As generative AI applications mature, engineering teams are finding that standard API endpoints often fall short on cost and performance. Companies increasingly need to customize and scale their own AI workloads to remain efficient. A recent engineering blog post from Notion illustrates this shift perfectly. To handle billions of vector embeddings, Notion overhauled its infrastructure by migrating both indexing and serving to Ray. The company noted that while tech giants build entire internal teams around open-source projects like Ray, Notion does not have a dedicated machine learning infrastructure team. Instead, they rely on a managed service from Anyscale to access these same enterprise-grade capabilities. This mirrors a broader industry trend toward the PARK stack, which consists of PyTorch, AI models, Ray, and Kubernetes. By adopting these interoperable open-source compute components, teams can efficiently pipeline CPU and GPU tasks, run open-weight models directly, and drastically reduce latency without being locked into a single vendor.