

Inside the High-Stakes World of Generative AI Red Teaming
We’re at a pivotal moment for GenAI: these systems are evolving at an astonishing pace, integrating seamlessly into our daily routines, yet bringing with them a host of new security and safety challenges. That’s why I find Microsoft’s recent study—where its AI Red Team conducted extensive security testing on over a hundred GenAI products—compelling and timely. It’s obvious why this study is necessary when you see how fast AI is moving, with new types of AI popping up and being used everywhere. As I’ve previously discussed, the importance of structured and consistent red teaming cannot be overstated, and Microsoft’s approach highlights the practical steps we can take to stay ahead. By blending automated tools with human expertise, Microsoft’s study highlights both the urgency of these threats and the practical steps we can take to stay ahead.
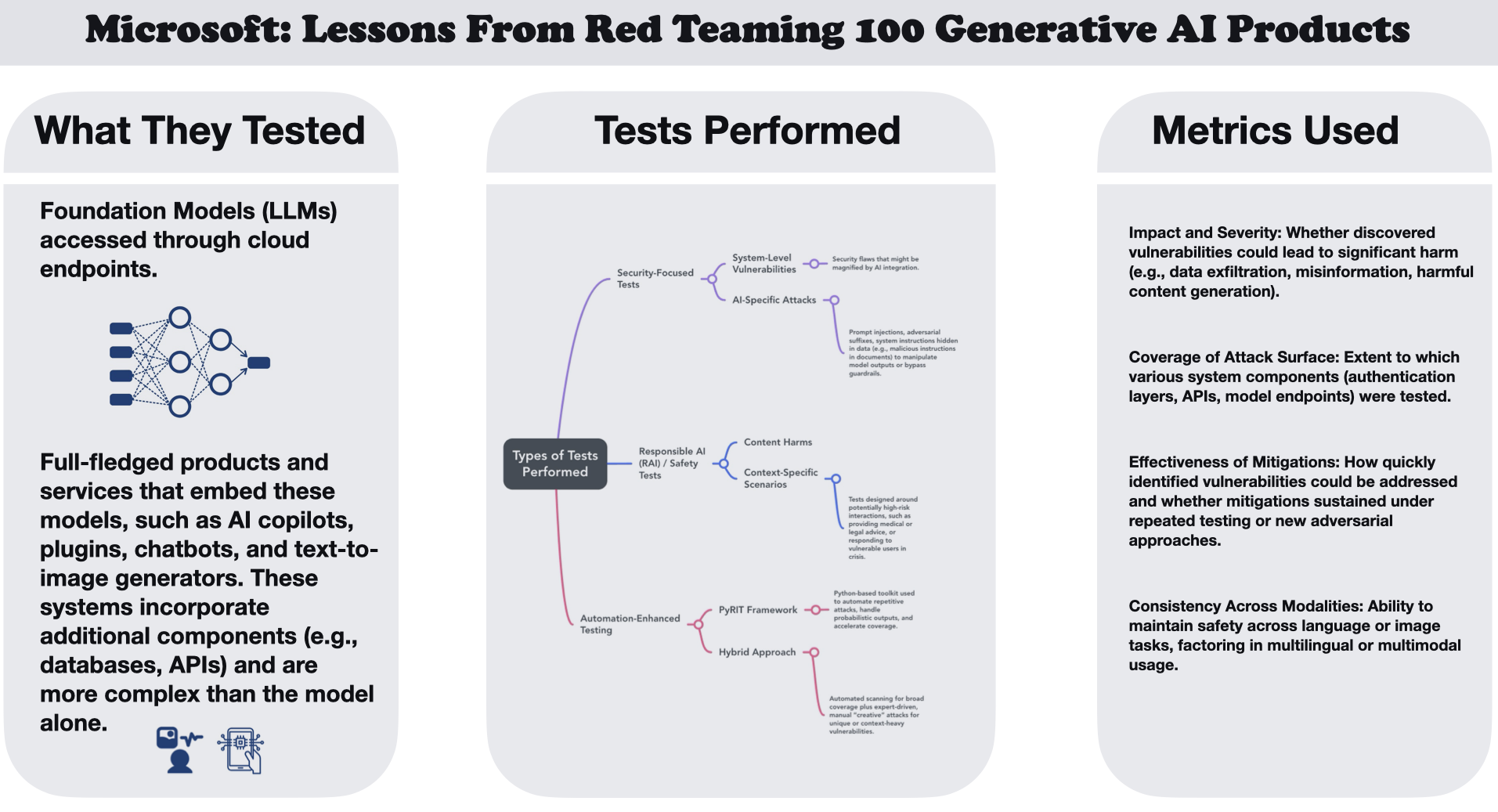
Microsoft’s AI Red Team systematically tested both core generative models and full-fledged AI systems—think chatbots, AI copilots, text-to-image generators, and more—to uncover vulnerabilities specific to GenAI. The team ran a mix of security-focused tests targeting system-level flaws like server-side request forgery and AI-specific exploits such as prompt injections, along with Responsible AI tests that examined how these models handle high-risk interactions, sensitive content, or potentially harmful outputs. The team used a hybrid approach: they employed the PyRIT framework to automate broad attacks while also relying on expert-driven, creative methods to root out subtler risks. Throughout the process, they evaluated their efforts based on how effectively they could mitigate security gaps, maintain coverage across different components, and ensure that safeguards remained consistent—even when the models were confronted with rapidly evolving threats or used in multilingual and multimodal contexts.

{kind=link}
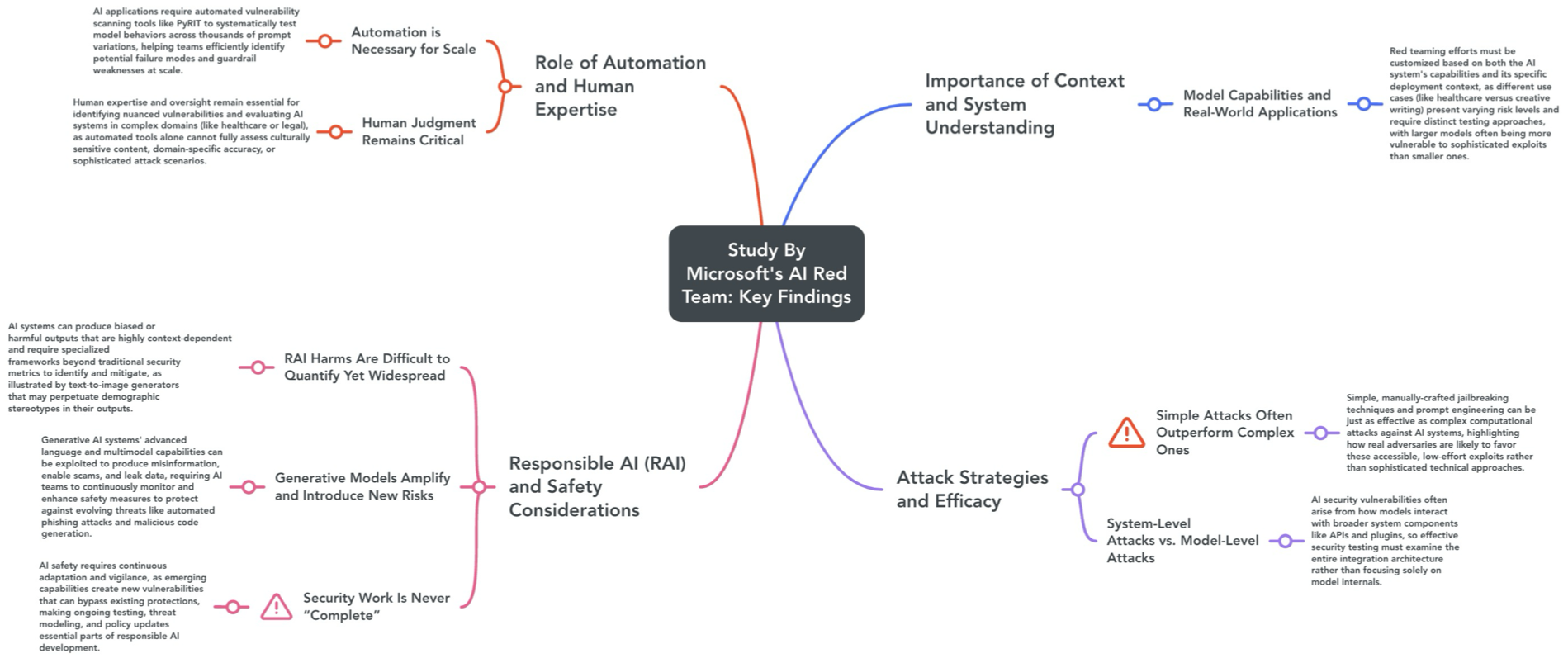
After rigorously testing over a hundred GenAI products, Microsoft’s AI Read Team assembled several findings that anyone building AI applications should keep front and center:
- Context is King. Effective red teaming requires a keen awareness of the specific tasks and real-world settings where an AI system operates. A chatbot dispensing mental health advice, for example, demands different threat modeling than a content generator, ensuring teams focus on the unique risks that each use case presents.
- Simplicity Often Wins. Straightforward exploits—like manual jailbreaking or prompt engineering—can be just as potent (if not more so) than advanced algorithmic attacks. This reminds me that real adversaries usually opt for the lowest-hanging fruit, so it’s crucial not to neglect basic, low-complexity vectors.
- It’s Not Just About the Model. Many vulnerabilities stem from system integration issues—APIs, plugins, and external databases—rather than the model alone. Even if a model is robust, insecure or poorly configured system components can quickly undo all that hard work.
- Automation is Essential, but Not a Panacea. Automated tools can methodically scan for common failures, but human creativity is indispensable for discovering nuanced or domain-specific flaws. For high-stakes applications—think healthcare or finance—this blend of automated coverage and expert-driven deep dives is non-negotiable.
- Responsible AI Harms are Tough to Quantify. Biases, harmful content, and misuse scenarios don’t neatly map to traditional security metrics. Product teams need dedicated frameworks to identify and measure these context-dependent risks, beyond just checking for typical vulnerabilities.
- Security is a Continuous Process. With AI advancing so rapidly, no single patch or set of guardrails can fully eliminate new threats as they emerge. Frequent re-testing, ongoing threat modeling, and iterative updates are vital for staying one step ahead of novel attacks.

{kind=link}
We need to shift how we approach AI security, moving beyond simply enumerating every possible exploit and focusing on the real-world implications of AI misuse. In my view, this is best achieved through comprehensive strategies that look beyond the model itself to scrutinize authentication endpoints, plugins, and external data flows. Although advanced adversarial methods do exist, it’s often the simple, low-complexity tactics that pose the biggest threat in practical scenarios. As I discussed in my AI Incident Response article, red teaming inevitably surfaces issues that demand well-defined containment and remediation steps—a critical link between proactive threat modeling and crisis management.
At the same time, balancing automated tools like PyRIT with hands-on, expert-driven evaluations is key—especially for complex or domain-specific risks, such as Responsible AI (RAI) harms and specialized regulatory fields like healthcare and finance. Human insight remains indispensable for recognizing nuanced issues like bias or culturally sensitive content that automated scanning alone might miss. This type of rigorous testing is a core component of the analysis and validation layer of an AI alignment platform, which we’ve previously argued is essential for managing AI risks holistically. Finally, it’s vital to adopt an iterative “break-fix” mindset: every new feature, model update, or system integration can introduce fresh vulnerabilities. By building this continuous testing loop into our development processes—and proactively seeking out context-dependent risks and harms—we stand a much better chance of creating secure and responsible AI systems that can weather the challenges of the real world.

{kind=link}
This study provides a solid foundation for approaching GenAI security but it does have limitations. The subjective nature of Responsible AI (RAI) harms—where definitions of “harmful” output can shift dramatically based on context or culture—poses a significant hurdle to creating universal standards. Moreover, because these findings are rooted in Microsoft’s internal product ecosystem, other organizations may need to adapt the recommendations to their own industries, usage contexts, and organizational structures. Finally, the ever-evolving nature of AI, marked by novel model behaviors and attack vectors, means that these insights should be seen as a starting point rather than a final blueprint.
Looking ahead, the path forward calls for broader standardization of red teaming methodologies, allowing teams across the industry to collaborate on shared metrics and best practices. We also need to continue refining automated tools, like PyRIT, so they can handle more data modalities, diverse prompts, and real-time adversarial strategies. Additionally, our efforts must expand to next-generation, agentic systems with greater autonomy—and include multilingual and multicultural testing to capture localized concepts of bias and safety. Finally, fostering open collaboration, from knowledge-sharing forums to open-source initiatives, will be critical for evolving AI security in a way that keeps pace with technological advances and ensures our systems remain powerful, yet fundamentally safe.
If you enjoyed this post, please consider supporting our work by leaving a small tip here and inviting your friends and colleagues to subscribe to our newsletter: