

A recent Stanford paper sheds light on a critical issue in AI-driven legal research tools: hallucinations. Hallucinations occur when AI models generate false or misleading information, which can have severe consequences in the legal domain. Legal professionals rely on accurate and authoritative information to make informed decisions, draft documents, and advise clients. Inaccurate information can lead to erroneous legal judgments, sanctions, and a general distrust in AI tools that are otherwise poised to enhance efficiency in legal research and practice.
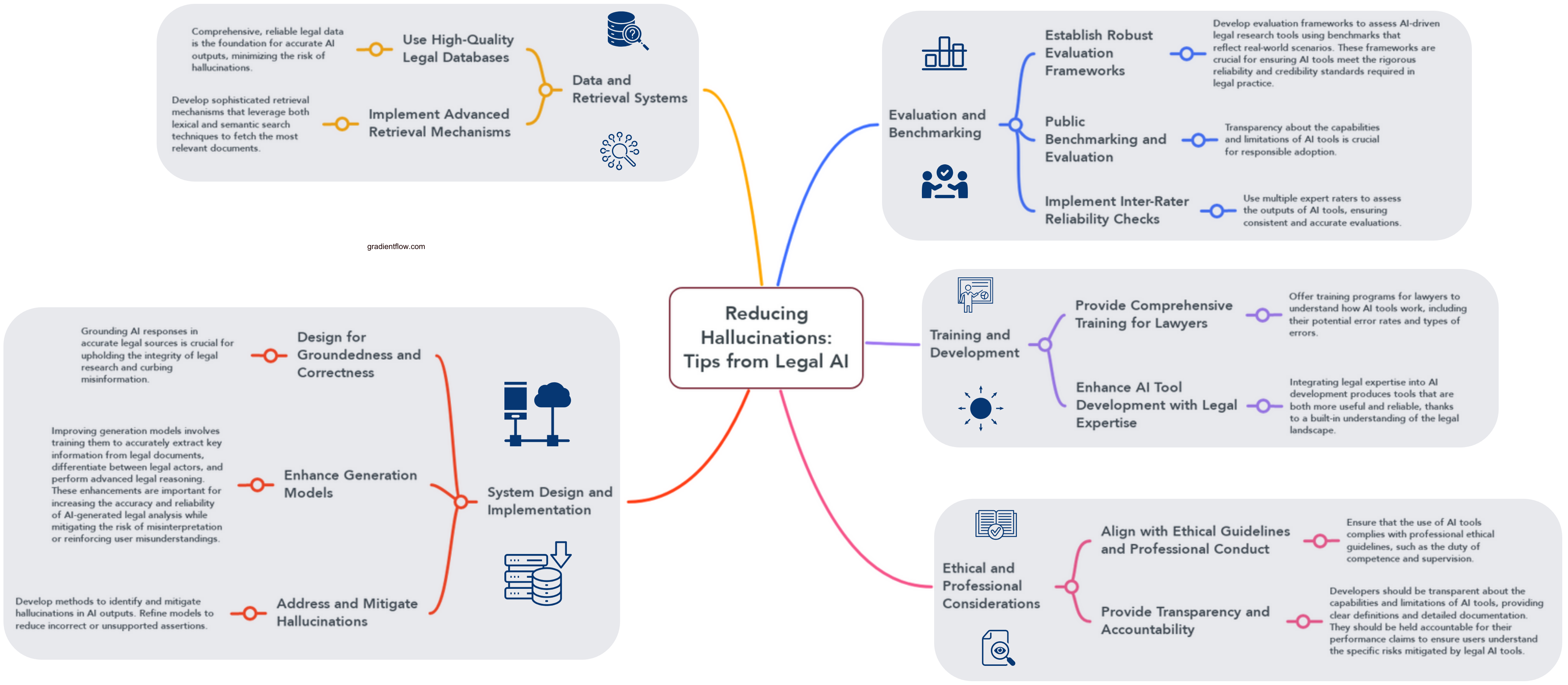
The researchers propose the use of Retrieval-Augmented Generation (RAG) systems, which integrate a language model with a database of legal documents to generate responses supported by authoritative legal sources. RAG involves two primary steps: retrieval and generation. First, the system retrieves relevant source material, and then it uses that material to generate the correct response. The goal is to reduce hallucinations by ensuring that the AI tools accurately cite authoritative sources and avoid misgrounded responses.

In addition to RAG, the researchers also propose implementing rigorous, transparent benchmarking and public evaluations of legal AI tools. This includes creating publicly available datasets for legal AI research, developing clear standards and metrics for assessing the performance of legal AI tools, and encouraging collaboration between developers and researchers to enable robust evaluation.
There are several challenges in implementing RAG-based legal AI systems and the proposed evaluation framework:
- Legal Retrieval Complexity: Legal documents vary across jurisdictions and evolve over time, complicating the retrieval process. Identifying documents that definitively answer a query is challenging.
- Source Applicability: Retrieved documents may not always be applicable or authoritative, necessitating meticulous validation, which can be resource-intensive.
- Text Generation Complexity: Generating meaningful legal text involves synthesizing facts, holdings, and rules from different sources while maintaining the appropriate legal context.
- Sycophancy: AI tools may agree with incorrect assumptions in user queries, leading to misinformation.
- Proprietary Data: Convincing legal AI companies to open their data and models for public evaluation is difficult due to competitive pressures.
- Evaluation Complexity: Evaluating legal AI tools is an expensive and complex process, requiring legal expertise and careful analysis.

{kind=link}
Lesson for AI teams
AI teams working in other domains can learn from this study in several ways:
- Best practices for evaluation: The development of shared evaluation metrics and datasets for legal AI will establish best practices for evaluating AI systems in other domains. This will help ensure transparency and accountability for AI models across the board. The rigorous evaluation methodology developed for legal AI tools, including the use of preregistered datasets and manual validation of outputs, can serve as a model for evaluating AI systems in other contexts to ensure reliability and trustworthiness.
- Error reduction: Understanding the mechanisms by which RAG reduces hallucinations can be applied to other high-stakes domains, such as healthcare, finance, or regulatory compliance, where the accuracy of AI-generated information is critical. The lessons learned from the legal domain can be applied to other domains where domain-specific knowledge is crucial. For example, AI teams working on contract analysis or document summarization can benefit from the insights on how to design high-quality research tools that deal with the problem of hallucinations.
- Improved retrieval techniques: The challenges faced in legal retrieval, such as handling complex, jurisdiction-specific queries, can inform the development of more sophisticated retrieval algorithms that are applicable in other fields. Additionally, the proposed solution highlights the importance of careful attention to non-textual elements of retrieval and the deference of the model to different sources of information, which can be applied to other domains.
- Building trust in AI: Robust evaluation and benchmarking help foster trust in AI systems. By demonstrating the reliability of legal AI tools, the research will contribute to building broader confidence in AI technology. Addressing issues of sycophancy and source verification in legal AI can enhance the transparency and user trust in AI systems across various industries by ensuring that AI outputs are grounded in authoritative and relevant data.
- Improving AI safety and robustness: The focus on identifying and addressing hallucinations in legal AI will lead to better understanding of how to mitigate similar errors in other AI applications. This can help AI teams improve the robustness, accuracy, and trustworthiness of their AI applications, leading to better user outcomes and increased adoption of AI technologies in sensitive and critical areas.

{kind=link}
A recent MIT paper challenges GPT-4’s reported bar exam success, emphasizing the need for rigorous and transparent AI evaluations. The findings suggest that GPT-4’s estimated 90th-percentile performance is likely overstated, with its actual performance falling below the 69th percentile overall and 48th percentile on essays when compared to a recent July exam administration. The paper also uncovers methodological issues in the grading of GPT-4’s essays, which deviated significantly from official protocols. These findings underscore the need for accurate, transparent evaluations and the cautious integration of AI in professional settings to ensure safety, reliability, and trust. Overestimating AI capabilities could lead to inappropriate reliance on AI for complex tasks, risking misapplication and professional malpractice.
Analysis
The Stanford paper’s findings underscore the importance of using language models effectively to avoid hallucinations and inaccuracies in AI-driven legal research tools. To ensure the reliability of these tools, it is crucial to implement methods such as verifying outputs against retrieved documents, incorporating relevant legal texts in prompts, and layering precedence and authority. Proper usage and oversight of LLMs are essential for developing trustworthy AI applications in the legal domain.
At present, AI’s potential lies in working alongside humans, supplementing rather than replacing human expertise. AI is a powerful tool that can enhance human capabilities, especially in research, analysis, and creative processes. Understanding the role of AI as a collaborative tool helps teams design applications that complement human expertise and ultimately improve outcomes for users.
There are valid concerns about the overhype surrounding AI and its potential misuse, which can lead to unrealistic expectations and subpar products. Overhyping AI’s capabilities may result in the development of tools that provide inaccurate or misleading information, potentially harming users. Being aware of the risks associated with overhype and misuse helps teams set realistic expectations and prioritize responsible AI development.
Another concern is the lack of transparency and explainability in LLMs, making it difficult to understand why they make certain decisions or generate specific outputs. Addressing the black box nature of LLMs is crucial for building trust and accountability in AI applications, particularly in sensitive domains like law, where the consequences of errors can be significant.
Related Content
- [Stanford paper] Assessing the Reliability of Leading AI Legal Research Tools
- [MIT paper] Re-evaluating GPT-4’s bar exam performance
- Balancing Act: LLM Priors and Retrieved Information in RAG Systems
- Navigating the Nuances of Retrieval Augmented Generation
- Enhancing RAG with Knowledge Graphs: Blueprints, Hurdles, and Guidelines
If you enjoyed this post please support our work by encouraging your friends and colleagues to subscribe to our newsletter: