

While large language models (LLMs) and foundation models have many promising applications, the lack of understanding of their internal workings has raised concerns about their safety and reliability. Without a clear grasp of how LLMs represent and process information, mitigating the risks of harmful, biased, or untruthful outputs remains a significant challenge. This article explores a solution proposed by Anthropic to address this problem, and its implications for AI teams building data applications.
AI models, especially LLMs, are often treated as black boxes, making it difficult to trust their outputs and ensure their safety. Unlocking their internal workings is crucial for building safer and more reliable AI systems. By understanding how LLMs represent and use knowledge, AI teams can develop tools to mitigate bias, detect harmful behaviors, and prevent misuse. This transparency fosters greater trust in AI systems, paving the way for their wider and more responsible adoption.

{kind=link}
Existing Tools and Their Limitations
Several tools have been developed to help us understand how AI models work internally. It’s akin to trying to understand a complex machine by looking at its gears and levers. One tool, called dictionary learning, tries to match patterns of activity within the AI model to concepts we can understand. It’s like trying to figure out what each gear does based on how it moves. However, this tool struggles when dealing with really large and complex AI models, like those used in today’s most powerful language models.
Another tool, linear probing, helps us understand how the AI model responds to specific questions or inputs. But, it requires creating a separate set of data for every question we want to ask. This makes it inefficient when dealing with a lot of different questions.
Then there’s sparse autoencoders which are like a specialized tool for identifying important parts of the AI model and how they work together. It’s like finding the key gears and levers that make the machine function. But, this tool sometimes makes mistakes. It might underestimate the importance of certain parts, like saying a big gear is actually small, making it hard to get a complete picture. This is called the “shrinkage” problem.
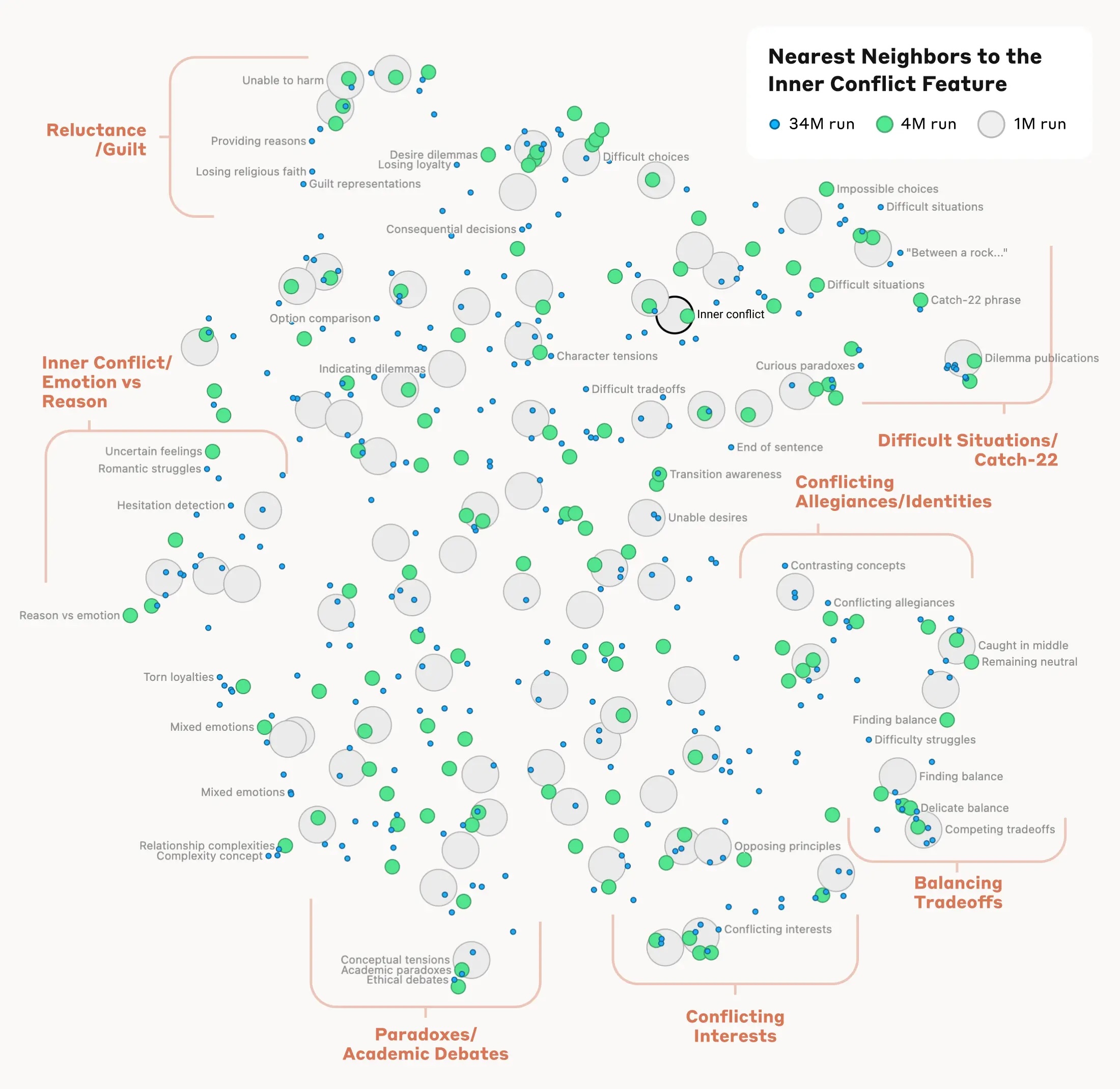
By identifying and manipulating interpretable features, AI teams can gain a deeper understanding of their model
Overall, these tools are still under development, and they often provide only a limited understanding of how AI models really work. They also require a lot of computing power and may not work well with the most advanced models common in Generative AI.
Scaling Dictionary Learning for Safer AI
The paper proposes a novel approach to understanding the inner workings of LLMs by scaling up dictionary learning techniques. Specifically, the researchers used sparse autoencoders to analyze Claude 3.0 Sonnet, a large, production-grade AI model. By training these autoencoders to break down the model’s internal activations into more interpretable components, the researchers were able to identify and manipulate millions of features representing diverse concepts. This approach provides a more detailed and comprehensive map of the model’s internal states.
The effectiveness of this method is supported by its successful application to Claude 3.0 Sonnet. The researchers identified millions of interpretable features, ranging from specific entities like cities and people to abstract ideas like “inner conflict.” Crucially, they demonstrated that manipulating these features resulted in predictable changes in the model’s behavior, confirming a causal link between the features and the model’s actions.
Understanding AI models is crucial for safer, more reliable systems
Anthropic’s proposed solution offers several benefits to AI teams:
- Deeper Model Understanding: By identifying and interpreting features related to specific concepts, users gain a deeper understanding of how their models represent and use knowledge. This insight is crucial for developing robust and reliable AI systems.
- Enhanced Safety Tools: With this newfound understanding, teams can develop tools to detect and mitigate harmful behaviors, such as bias, deception, and the generation of dangerous content.
- Improved Model Development: Feature manipulation allows developers to steer models towards desired outcomes, like reducing bias or promoting honesty, leading to more ethical and reliable AI systems.
- Increased Transparency and Trust: By controlling specific features within the model and increasing transparency into its internal workings, teams can improve AI safety and reliability, fostering greater trust in these systems.
Conclusion
While this proposed solution holds significant promise, it faces several limitations. The computational cost of identifying a complete set of features remains a significant hurdle, and the current feature set is likely incomplete. The complexity of LLMs also presents challenges, as features can be “smeared” across multiple layers (cross-layer superposition), making it difficult to fully understand their individual roles. Furthermore, our understanding of the concept of superposition itself, along with how these features are actually used by the model, is still evolving.
Scaling dictionary learning techniques, such as sparse autoencoders, to large AI models like Claude 3.0 Sonnet offers a promising approach to unraveling the black box of AI models. By identifying and manipulating interpretable features, AI teams can gain a deeper understanding of their models, develop safety tools, and enhance model development. Let’s get a Ray implementation of the techniques from the paper up and running for Llama 3!
Related Content
- Early Thoughts on Claude 3
- From Supervised Fine-Tuning to Online Feedback
- Managing the Risks and Rewards of Large Language Models
- Get Started on Aligning AI
- A Critical Look at Red-Teaming Practices in Generative AI
If you enjoyed this post please support our work by encouraging your friends and colleagues to subscribe to our newsletter: