

Compute-intensive applications that incorporate machine learning should be built on top of Ray.
By Ben Lorica and Ion Stoica.
[This post originally appeared on the Anyscale blog.]
Introduction
As machine learning and AI become prevalent in software services and applications, most backend platforms now consist of business logic and machine learning (inference). Business logic and model inference have traditionally been handled by different systems. This post describes how Ray breaks down silos by supporting both these workloads seamlessly, allows developers to build and scale microservices as if they were a single Python application, and shows how companies use Ray for a wide range of applications.
How Companies use Ray
Previous posts and talks have described why Ray is a great substrate for building machine learning applications and platforms. Many companies have reached the same conclusion. The 2020 Ray Summit had presentations from companies who use Ray in machine learning and other applications including enterprises (Goldman Sachs, Dow Chemical, Linkedin), cloud platforms (AWS, Azure), and startups (Weights & Biases, Pathmind, SigOpt). The conference also included presentations from leading open source data and ML projects – Hugging Face, Horovod, Seldon – who use Ray for distributed computing.
More recently Uber used Ray to add elastic capabilities to Horovod, their popular distributed training framework. The quote below shows that this was just the first step for Uber – the company plans to consolidate their deep learning stack onto Ray.
- ❛ We believe that Ray will continue to play an increasingly important role in bringing much needed common infrastructure and standardization to the production machine learning ecosystem, both within Uber and the industry at large.
A keynote from Ant Group showcased a fusion engine used to power many services including ML, stream processing, analytics, and graph applications. This fusion engine is built with Ray and has successfully supported large-scale activities such as last year’s Double 11, the largest ecommerce shopping event in the world. Philipp Moritz (co-founder of Anyscale) gave a talk describing how Anyscale used Ray to build a Python web application – the Anyscale compute platform.
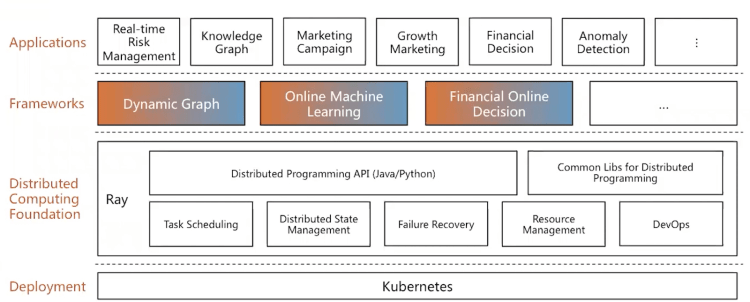
These two presentations, along with conversations we’ve had with companies already using Ray, highlight how Ray is being used in compute-intensive and long running applications.
Ray is a great substrate for building AI applications
AI applications combine machine learning models with business logic. As we noted in previous posts, Ray provides great support and libraries for data processing, machine learning and analytic workloads. Beyond distributed training, hyperparameter tuning, and reinforcement learning, the Ray ecosystem provides tools for the development, deployment, and management of machine learning models needed for AI applications. For example, in an earlier post we highlighted a new library that simplifies the creation of AI applications:
- ❛ Ray Serve brings model evaluation logic closer to business logic by giving developers end-to-end control from API endpoint, to model evaluation, and back to the API endpoint.
The ecosystem of tools that users can seamlessly combine also continues to grow. Since the start of the year, several popular open source machine learning and data libraries have turned to Ray for their distributed computation needs. Expect to see more of your favorite libraries use Ray in the months ahead.
Ray provides a unified programming model for building distributed applications
Ray supports multiple programming paradigms including functional programming, object oriented programming with actors, and asynchronous programming. This makes it easy for developers to build and parallelize services that power a range of applications.
Tasks: Ray enables arbitrary functions to be executed asynchronously. These “remote functions” (or tasks) have very low overhead, can be executed in milliseconds, and are great for scaling computationally intensive applications and services. If all the cores in the system are fully utilized, Ray can automatically add nodes to the cluster and schedule the tasks.
Actors: The Actor model is a powerful programming paradigm that allows for microservice based applications. It focuses on the semantics of message passing and works seamlessly when local or remote. Ray supports actors that are stateful workers (or services). Actors can be used for performance reasons (like caching soft state or ML models), or they could be used for managing long living connections to databases or to web sockets. Ray actors can be asynchronous, a feature that has proven useful for handling I/O heavy workloads like communicating with other web services.
Having a platform that supports stateful computations dramatically increases the number of possible applications. For example stateful operators allow Ray to efficiently support streaming computations, machine learning model serving, and web applications. All these advantages are available to Python and Java developers. For example the actor model described above is completely accessible to developers comfortable with Python (Erlang or Akka are no longer required).
Out of the box fault tolerance, resource management, and efficient utilization
For most applications, Ray takes care of fault-tolerance and recovery enabling developers to build robust applications. Ray also supports automatic scheduling and fine-grained resource management. This means developers can take advantage of specialized hardware like GPUs and TPUs. Developers don’t need to worry about physical nodes and resources and can instead focus on their application and business logic. Ray also automatically scales clusters based on utilization. This makes it possible to adapt to user demand: developers can increase capacity when demand is high and save costs when demand is low. All of this happens automatically.
Tools for testing distributed applications
Distributed applications are often very hard to test. Ray comes with a few features that make testing more convenient:
- Unit testing: Ray local mode allows developers to run their programs in a single address space executing tasks sequentially instead of in parallel. Since everything runs in a single process, developers can use tools like mock to write and run unit tests at any level of granularity.
- Integration testing: You can run Ray on a laptop, on a cluster, or on your continuous integration server to test components of your system (such as your business logic, web logic, machine learning models, and database).
Tools for application deployment, monitoring, and observability
Ray integrates with and runs on top of Docker and Kubernetes. Ray also has built-in facilities for monitoring which makes it easy to detect problems during the deployment of your AI application or web service. Ray exposes APIs to collect application specific metrics that can be exposed to a system like Prometheus where they can be queried and visualized.
Ray can handle low-latency, high-throughput applications
Ray is well-suited for a broad range of low-latency, resource-intensive applications. In a previous post we explained why Ray is the right foundation for a general purpose serverless framework. We noted that Ray’s support for fine-grained and stateful computations allows it to efficiently support streaming computations, machine learning model serving, and web applications. Ray also has high-performance libraries that can be used in many different types of applications. A new library called Ray Serve is suitable not just for machine learning but for any type of Python microservices application.
For these reasons, Ray is also an ideal fit for a compelling new programming model (“microservices that trigger workflows that orchestrate serverless functions”) aimed at resource-intensive workflows that “can last anywhere from minutes to years”.
Ray will simplify your architecture and lower your operational costs
Using Ray will reduce the number of libraries and frameworks you need to use to build your distributed application. In his Ray Summit talk, Philipp Moritz shared a high-level architecture of the Anyscale platform (a web application). By using Ray, Anyscale reduced the number of external libraries they needed and this simplified programming, monitoring, tracing, debugging, DevOps, and fault tolerance. We are aware of many other similar examples from companies who are using Ray to build AI applications and services.

Summary
Ray is a great platform for building a diverse set of compute-intensive applications. It is being used for a wide variety of use cases such as data and AI applications and platforms, to long running applications like web services. Ray comes with several native libraries and also integrates and powers many popular libraries in the Python ecosystem. As described in this post, Ray is flexible, scalable, and comes with tools for testing, deployment, and monitoring.
It has already been used in large-scale production applications. If you would like to find out more about how Ray is being used in industry, please visit the Ray Summit page. If you are thinking of developing a distributed application – a compute-intensive application that incorporates machine learning – consider building it on top of Ray.
[Photo by from PxHere.]