The Industrialization of Synthetic Data
Synthetic data used to be a fairly narrow idea: pad a small dataset, test a model without touching production data, maybe stress a system for bias. The rise of generative AI and autonomous agents has changed the landscape. Teams use synthetic data to train and evaluate agentic systems, to cover rare failure cases, to meet privacy and compliance requirements, and to simulate workflows that look more like real work than like a benchmark. As the use cases expanded, the “just generate more rows” mindset stopped working, and synthetic data started to look like an engineering system that needs real infrastructure.
Compute intensive, in this context, means two things. First, the cost per synthetic example is going up because each example is longer, more interactive, and often requires multiple model calls. Second, the pipeline around generation is getting heavier: validation, deduplication, tool execution, sandboxes, storage, and orchestration. This complexity has effectively turned synthetic data generation into an industrial-scale engineering problem.
Been reading for a while? Support our work by becoming a paid subscriber.
The unit of data got bigger
Modern synthetic data is no longer just a short question and answer. It has evolved into long sequences of steps that include planning, reasoning, and using external tools. At the same time, we are asking models to show their work by producing step-by-step reasoning traces. If a single high-quality training example now spans thousands of tokens and dozens of steps, you need far more computing power to produce it. This is especially true for AI agents that must try a task, fix their own mistakes, and finish a job rather than just giving a quick response.

{kind=link}
One example now takes a small team of models
Many pipelines have moved from a single model call per example to a coordinated workflow of different agents. One agent might select a persona, another generates the content, and a third refines the tone. When you multiply this by millions of examples, the total number of inference calls scales rapidly. In practice, teams building research assistants or customer-support agents find that synthetic data generation is actually a complex set of separate inference jobs that require sophisticated scheduling and tracking.
Quality control became its own workload
Because these sequences can be long, checking the work is no longer a simple final check. A tiny mistake at the start of a plan makes everything that follows a waste of time. To catch these errors, teams now use a second AI to judge every single step the first one takes. If a task has twenty steps, you might run fifty separate AI operations just to get one usable result. When you scale that to millions of examples, the demand for processing power explodes.

“Trust but verify” requires running code
For agents that use tools, a frequent failure is when the model claims it finished a task but actually failed. To solve this, pipelines now include executable validators. This means running Python scripts or checking API returns in real time to see if the code actually works. This pushes the compute burden away from pure GPU inference and into CPU, memory, and sandbox capacity, often requiring thousands of parallel, isolated containers to verify that the generated data is actually correct.
Realism demands real tools and environments
If you want to teach an agent to browse the web or use enterprise software, you cannot simply fake the responses. Teams are increasingly executing real tool calls and managing the associated rate limits, timeouts, and connectivity. For “computer use” training, the cost jumps significantly because you are running full virtual machines with browser engines and GUI rendering. This looks less like a data script and more like operating a massive virtual desktop fleet.

Keeping data diverse is a heavy lift
Once you can generate data at scale, the bottleneck shifts to keeping that data varied. Production pipelines now generate massive numbers of candidate items, then use embedding models and clustering to deduplicate them aggressively. This requires large-scale embedding runs and significant compute spent on items that are ultimately discarded. This is a major hurdle for teams building enterprise copilots that need to handle a vast range of departments, personas, and edge cases without repeating themselves.
Higher-fidelity generators raise the per-sample price
In specialized fields like medical imaging, simple simulations are no longer enough. Generating high-resolution 3D images to train diagnostic AI requires advanced models that are much slower than older methods. Because training loops consume data faster than a single generator can produce it, teams often have to run massive GPU pools just to ensure the training process does not sit idle while waiting for the next batch of images.

Synthetic data is turning into an always-on factory
Static datasets go stale quickly for interactive agents. Modern systems use a continuous loop where the agent interacts with environments and logs new experiences throughout the training process. This means your demand for computing power does not end once the data is collected. It persists throughout the entire life of the model. Keeping training and generation in sync becomes a major systems engineering challenge, requiring a production-grade service with its own monitoring, fault tolerance, and distributed infrastructure.
The rise of these data factories is another reason to modernize your AI infrastructure.
Putting the Pieces Together: Synthetic Data in Production Mode
A system from Meta called Matrix shows how these requirements come together in a single synthetic data factory. It was built to create data for complex tasks like customer service and web research. These jobs require multiple AI agents to work together, which is much harder to manage than a simple question and answer script.
Matrix targets large-scale data generation where each “item” is not a single prompt-response, but an end-to-end workflow. Every task carries its own instructions and history as it moves between different AI agents. This design gets rid of a central controller that often slows things down. By letting each task move forward on its own, the system avoids the idle time that usually happens when computers have to wait for a large batch of work to finish.
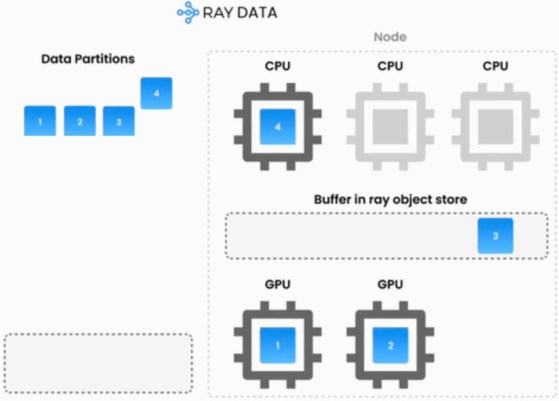
The setup highlights how much infrastructure this requires. Matrix is built on an open-source stack (SLURM and Ray) and uses containerized execution (Apptainer) for tool and environment interaction, while compute-intensive operations like LLM inference and container workloads are handled as distributed services that can scale independently from the agents. In one test, the system handled over 12,000 tasks at once and produced 2 billion tokens of text in about four hours. For tasks that involve using real software tools, it can run 1,500 containers at the same time to verify that the results are accurate.

The rise of these data factories is another reason to modernize your AI infrastructure. Synthetic data pipelines now look like production systems that mix GPU-heavy generation and embedding runs with CPU-heavy filtering and tool execution. They also create a lot of read and write traffic as you iterate. A multimodal lakehouse is a sensible data layer for this work because it stores raw media alongside embeddings and features. It also feeds training and inference jobs without letting storage become a bottleneck that leaves GPUs waiting.
The compute side maps cleanly to the PARK stack. Kubernetes provides the cluster foundation and Ray coordinates the complex mix of distributed tasks to keep pipelines moving. PyTorch and your frontier models then handle the generation and training loops. This approach offers a practical way to treat synthetic data as a core part of your platform. It provides a durable place to store and query what you generate and a reliable way to scale the services that produce it.
Building these data factories does more than just improve reasoning and agent behavior. It provides the scale needed to train models on the multi-table databases that most companies rely on. Done well, synthetic data ceases to be a stopgap and becomes a practical path to better business models, including things like churn, fraud, and forecasting.
You Don’t Need a Massive ML Team to Scale AI Affordably
As generative AI applications mature, engineering teams are finding that standard API endpoints often fall short on cost and performance. Companies increasingly need to customize and scale their own AI workloads to remain efficient. A recent engineering blog post from Notion illustrates this shift perfectly. To handle billions of vector embeddings, Notion overhauled its infrastructure by migrating both indexing and serving to Ray. The company noted that while tech giants build entire internal teams around open-source projects like Ray, Notion does not have a dedicated machine learning infrastructure team. Instead, they rely on a managed service from Anyscale to access these same enterprise-grade capabilities. Just as we saw with synthetic data pipelines, this migration is the PARK stack at work. By adopting these interoperable open-source compute components, teams can efficiently pipeline CPU and GPU tasks, run open-weight models directly, and drastically reduce latency without being locked into a single vendor.