

Balancing Innovation and Risk: The Dual-Edged Sword of Generative AI
Generative AI has the potential to revolutionize numerous industries, but it also carries significant risks that must be carefully considered and mitigated. The Federal Office for Information Security, the agency responsible for managing computer and communication security for the German government, has recently released a comprehensive taxonomy that outlines the various risks associated with the use of large language models (LLMs).
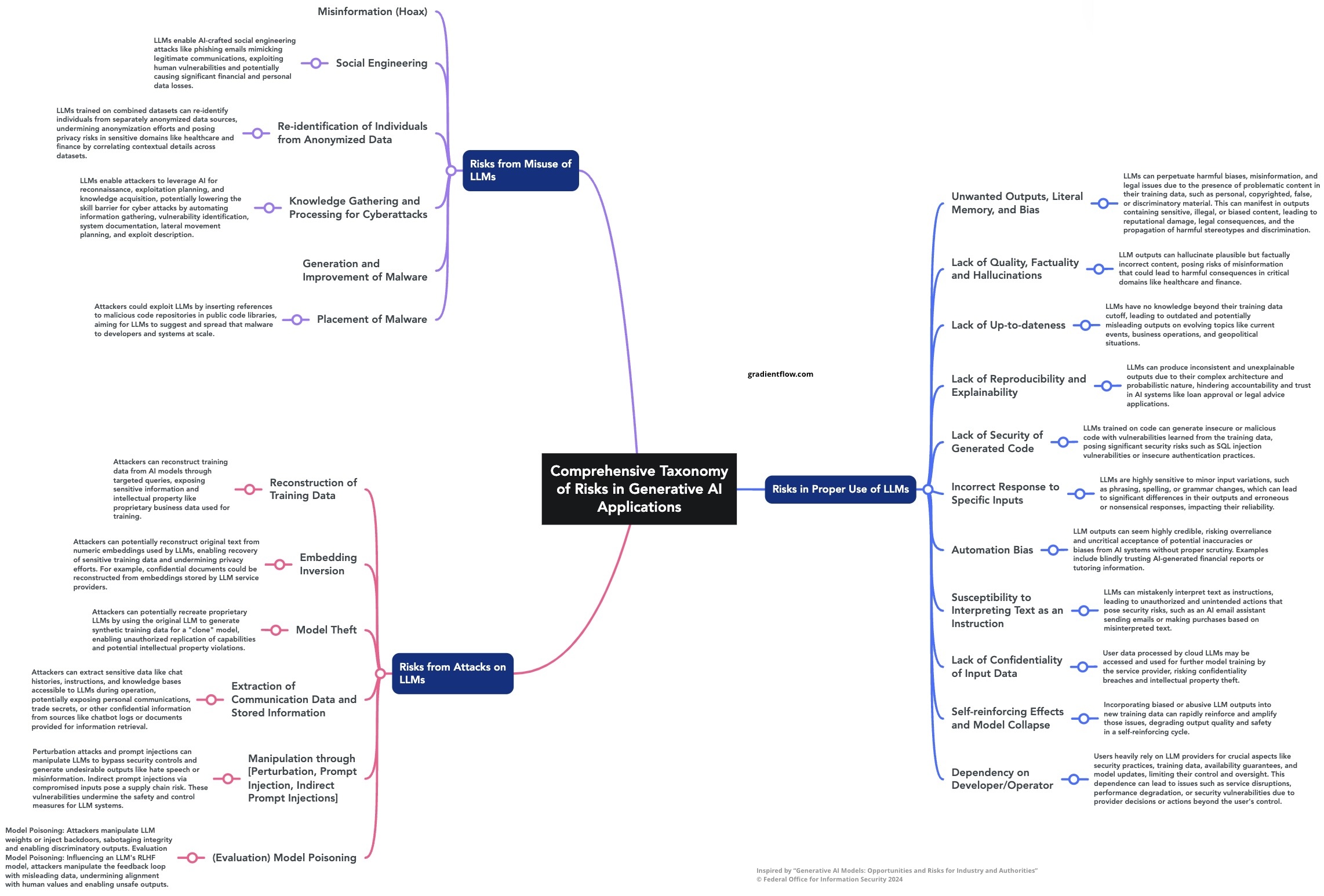
One crucial category that deserves particular attention is the “Risks in Proper Use of LLMs.” This category encompasses a range of potential issues that can arise even when LLMs are used as intended, without any malicious intent. Understanding and addressing these risks is crucial, as they can have profound consequences for businesses, individuals, and society at large.
Even proper use of LLMs carries significant risks
One of the key risks in this category is the potential for unwanted outputs, literal memory, and bias. LLMs are trained on vast datasets that may contain personal, copyrighted, false, discriminatory, or biased content. As a result, these models can inadvertently perpetuate harmful biases and misinformation through their generated outputs, leading to legal issues, reputational damage, and the perpetuation of harmful stereotypes and discrimination.
Another significant risk is the lack of security of generated code. LLMs trained on code can generate insecure or malicious code, introducing vulnerabilities learned from the training data. This poses a severe security risk, as generated code with vulnerabilities can be exploited, potentially leading to disastrous consequences.

{kind=link}
Automation bias is another critical issue that must be addressed. The human-like quality of LLM outputs can lead to overreliance and unquestioning trust in their accuracy. This over-reliance can result in the acceptance of incorrect or biased information without proper scrutiny, potentially leading to poor decision-making and adverse outcomes.
LLMs are also susceptible to interpreting text as an instruction, which can lead to unauthorized actions and security vulnerabilities. This risk highlights the importance of implementing robust safeguards and controls to prevent unintended actions by LLM systems.
Finally, the taxonomy identifies self-reinforcing effects and model collapse as potential risks. Overrepresentation of certain data points can cause models to produce repetitive and biased outputs, leading to a self-reinforcing cycle of biases and misinformation. This can perpetuate harmful stereotypes and undermine the integrity of the model’s outputs.
For teams building AI applications and solutions, it is crucial to understand and address these risks proactively. Ignoring or underestimating these risks can have severe consequences, ranging from legal and reputational damage to the perpetuation of harmful biases and discrimination. By staying informed and implementing robust risk mitigation strategies, we can harness the power of generative AI while minimizing its potential negative impacts.
Related Content
- Judicial AI: A Legal Framework to Manage AI Risks
- Managing the Risks and Rewards of Large Language Models
- What We Can Learn from the FTC’s OpenAI Probe
If you enjoyed this post please support our work by encouraging your friends and colleagues to subscribe to our newsletter: