
Privacy-preserving analytics is not only possible, but with GDPR about to come online, it will become necessary to incorporate privacy in your data products.
In this post, I share slides and notes from a talk I gave in March 2018 at the Strata Data Conference in California, offering suggestions for how companies may want to build analytic products in an age when data privacy has become critical. A lot has changed since I gave this presentation: numerous articles have been written about Facebook’s privacy policies, its CEO testified twice before the U.S. Congress, and I deactivated my mostly dormant Facebook account. The end result being that there’s even a more heightened awareness around data privacy, and people are acknowledging that problems go beyond a few companies or a few people.
Let me start by listing a few observations regarding data privacy:
- We tend to talk about data privacy in the context of security breaches, but there are many instances when privacy violations involve people who have been granted access to data.
- The growing number of connected devices enabled to collect data means our most sensitive data—see this article on smart homes—are being gathered and monetized.
- Concerns about the use of data privacy cuts across cultures. As someone who travels to China, I can attest that users there are just as concerned about how companies are using their data.
- It is true that regulators across the world are approaching data privacy in different ways. To the extent that many companies conduct business in the EU, the upcoming General Data Protection Regulation (GDPR) will influence how organizations across the world build and design data services and products.
Which brings me to the main topic of this presentation: how do we build analytic services and products in an age when data privacy has emerged as an important issue? Architecting and building data platforms is central to what many of us do. We have long recognized that data security and data privacy are required features for our data platforms, but how do we “lock down” analytics?
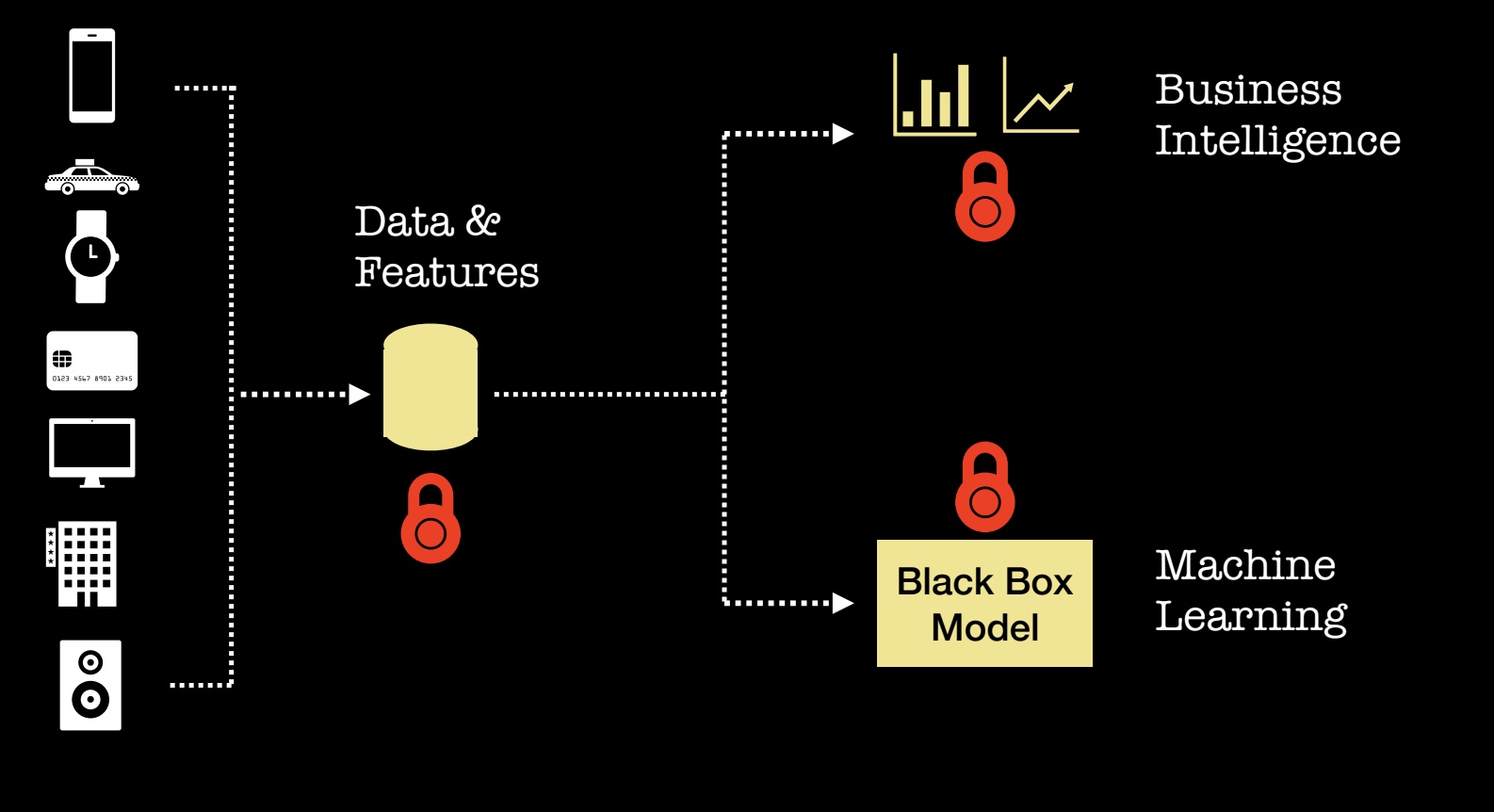
Once we have data securely in place, we proceed to utilize it in two main ways: (1) to make better decisions (BI) and (2) to enable some form of automation (ML). It turns out there are some new tools for building analytic products that preserve privacy. Let me give a quick overview of a few things you may want to try today.
Business intelligence and analytics
For most companies, BI means a SQL database. Can you run SQL queries while protecting privacy? There are already systems for doing BI on sensitive data using hardware enclaves, and there are some initial systems that let you query or work with encrypted data (a friend recently showed me HElib, an open source, fast implementation of homomorphic encryption).
Let me describe a recent collaboration between Uber and UC Berkeley’s RISE Lab.
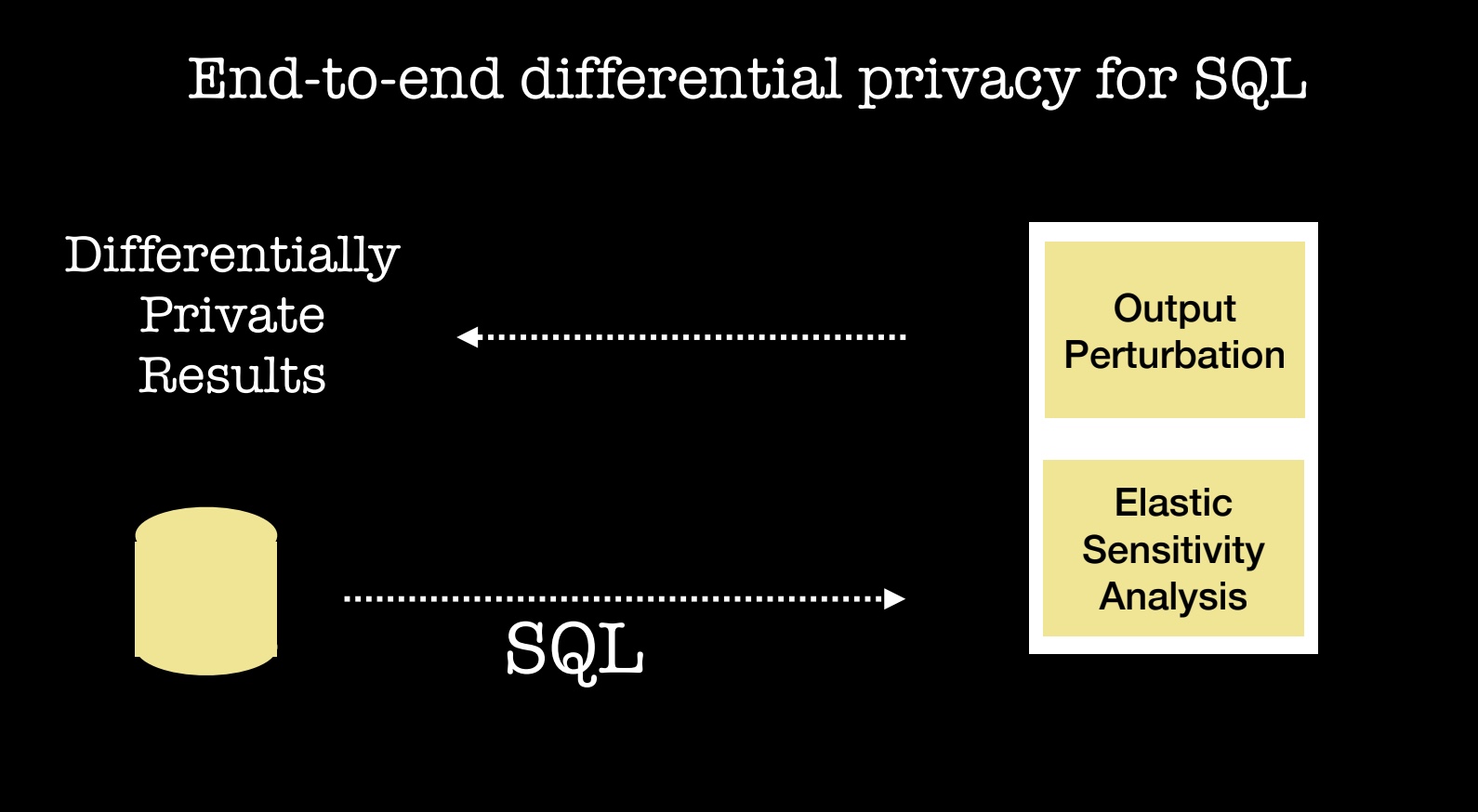
Their joint analysis of millions of queries executed at Uber led to a system that lets analysts submit queries and get results that adhere to state-of-the-art differential privacy (a formal guarantee that provides robust privacy assurances). As I mentioned above, privacy violations can involve people who have been granted access to data. What this new Uber/RISE Lab system implies is that analysts can be granted access to a database to do their standard SQL-based analysis, while data privacy is preserved. Their system is open source and can be used with any SQL database, and it is being used in a pilot deployment within Uber (see the paper and code).
This takes care of BI for reports that rely on SQL databases. But can one build a privacy-preserving BI system that gathers real-time data from millions of users? The answer is “yes”: recent announcements from Apple and Google detail analytic tools designed to help them understand how users interact with devices. For example, Apple and Google analysts can run queries to help them gather aggregate typing statistics and browsing behavior.

Apple described their system in a detailed blog post:
Our system is designed to be opt-in and transparent. No data is recorded or transmitted before the user explicitly chooses to report usage information. Data is privatized on the user’s device using event-level differential privacy in the local model where an event might be, for example, a user typing an emoji. Additionally, we restrict the number of transmitted privatized events per use case. The transmission to the server occurs over an encrypted channel once per day, with no device identifiers. The records arrive on a restricted-access server where IP identifiers are immediately discarded, and any association between multiple records is also discarded. At this point, we cannot distinguish, for example, if an emoji record and a Safari web domain record came from the same user. The records are processed to compute statistics. These aggregate statistics are then shared internally with the relevant teams at Apple.
Other companies like Microsoft are developing similar systems involving other smart devices.
Machine learning
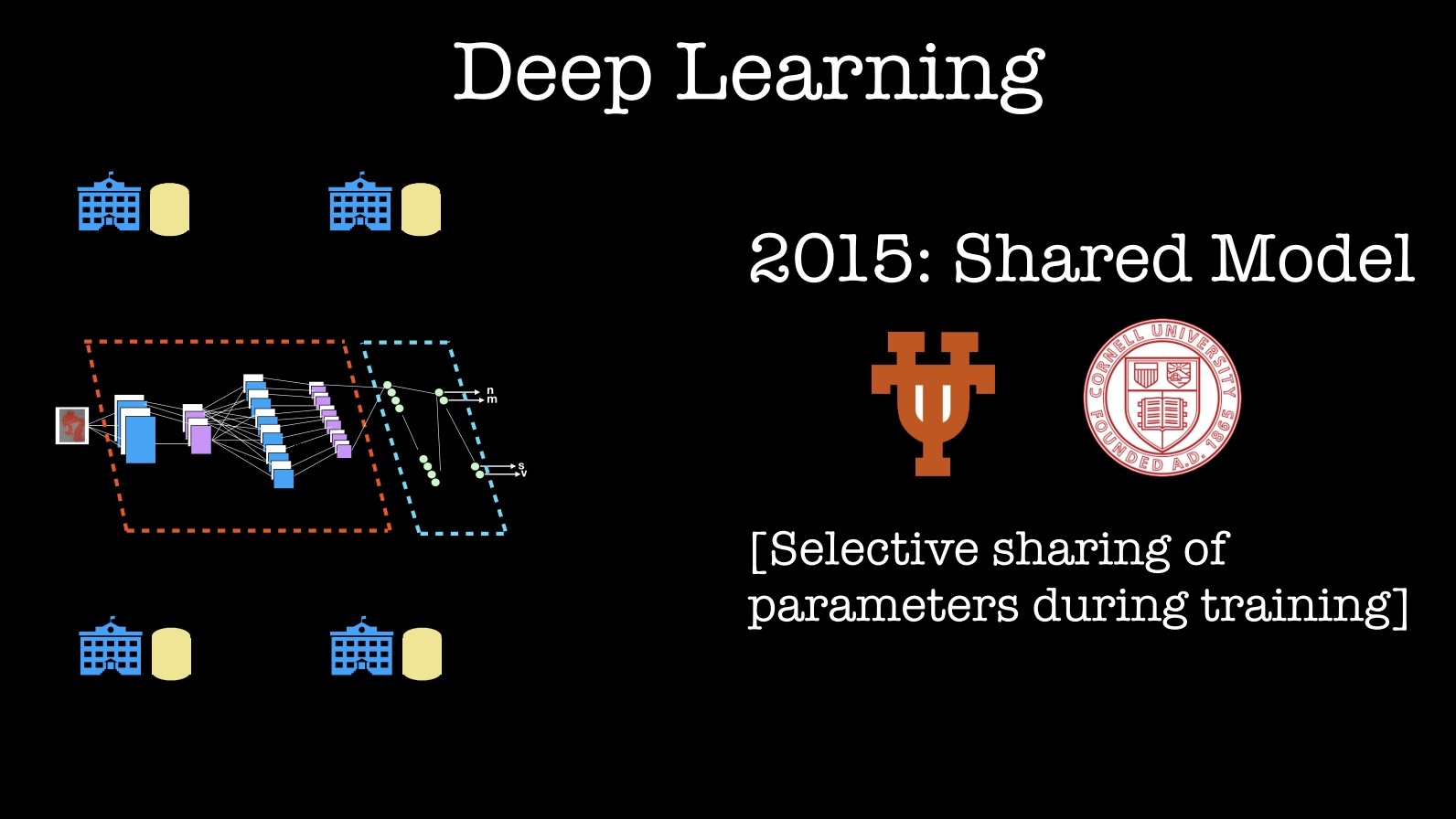
For machine learning, let me focus on recent work involving deep learning (currently the hottest ML method). In 2015, researchers at the University of Texas and Cornell University showed that one can “design, implement, and evaluate a practical system that enables multiple parties to jointly learn an accurate neural network model for a given objective without sharing their input data sets.” One application could be medical institutions wanting to build and learn a more accurate, joint model, without sharing data with people outside their respective organizations.
In 2016, Google took this “shared model” concept and scaled it to edge devices! They use it for products such as On-Device Smart Reply and their Mobile Vision API. This new system, which they dubbed “Federated Learning”, is able to leave training data distributed on the mobile devices, while learning a shared model by aggregating locally computed updates:

The two previous examples involve learning a shared (single) model, without sharing data. There might be instances where you want a highly personalized model, or you might have natural (demographic/usage) clusters of users that would benefit from more specifically tuned models. These scenarios were the focus of recent work by researchers at Stanford, CMU, and USC: they used ideas from multi-task learning to train personalized deep learning models. In multi-task learning, the goal is to consider fitting separate but related models simultaneously.

Closing thoughts
My main message is that privacy-preserving analytics is very much possible and something you should consider today—both for BI and machine learning. It is not only the right thing to do for your users, with GDPR about to come online, privacy becomes necessary to incorporate in your data products:
At its core, privacy by design calls for the inclusion of data protection from the onset of the designing of systems, rather than an addition.
One last thing: the two technology trends I’m following very closely are automation (AI) and decentralization (blockchain, crypto, and more). There are people actively working on rebuilding key services—identity management, data storage, payments, data exchanges, social media—and moving them away from centralized systems. I believe that the data science and big data communities are well-positioned to contribute to both automation and decentralization. Our community has spent years working on productionizing important building blocks—machine learning and distributed systems—that will remain at the core of future platforms.
[A version of this post appears on the O’Reilly Radar.]
Related content:
- “We need to build machine learning tools to augment machine learning engineers”
- “The ethics of artificial intelligence”
- Your data is being manipulated: danah boyd explores how systems are being gamed, how data is vulnerable, and what we need to do to build technical antibodies.
- “It’s time for data ethics conversations at your dinner table”
- Haunted by data: Maciej Ceglowski makes the case for adopting enforceable limits for data storage.