
We need to build machine learning tools to augment our machine learning engineers.
In this post, I share slides and notes from a talk I gave in December 2017 at the Strata Data Conference in Singapore offering suggestions to companies that are actively deploying products infused with machine learning capabilities. Over the past few years, the data community has focused on infrastructure and platforms for data collection, including robust pipelines and highly scalable storage systems for analytics. According to a recent LinkedIn report, the top two emerging jobs are “machine learning engineer” and “data scientist.” Companies are starting to staff to put their data infrastructures to work, and machine learning is going become more prevalent in the years to come.

As more companies start using machine learning in products, tools, and business processes, let’s take a quick tour of model building, model deployment, and model management. It turns out that once a model is built, deploying and managing it in production requires engineering skills. So much so that earlier this year, we noted that companies have created a new job role—machine learning (or deep learning) engineer—for people tasked with productionizing machine learning models.
Modern machine learning libraries and tools like notebooks have made model building simpler. New data scientists need to make sure they understand the business problem and optimize their models for it. In a diverse region like Southeast Asia, models need to be localized, as conditions and contexts differ across countries in the ASEAN.
Looking ahead to 2018, rising awareness of the impact of bias, and the importance of fairness and transparency, means that data scientists need to go beyond simply optimizing a business metric. We will need to treat these issues seriously, in much the same way we devote resources to fixing security and privacy issues.

While there’s no comprehensive checklist one can go through to systematically address issues pertaining to fairness, transparency, and accountability, the good news is that the machine learning research community has started to offer suggestions and some initial steps model builders can take. Let me go through a couple of simple examples.
Imagine you have an important feature (say, distance from a specific location) of a machine learning model. But there are groups in your population (say, high and low income) for which this feature has very different distributions. What could happen is that your model would have disparate impact across these two groups. A relevant example is a pricing model introduced online by Staples: the model suggested different prices based on location of users.
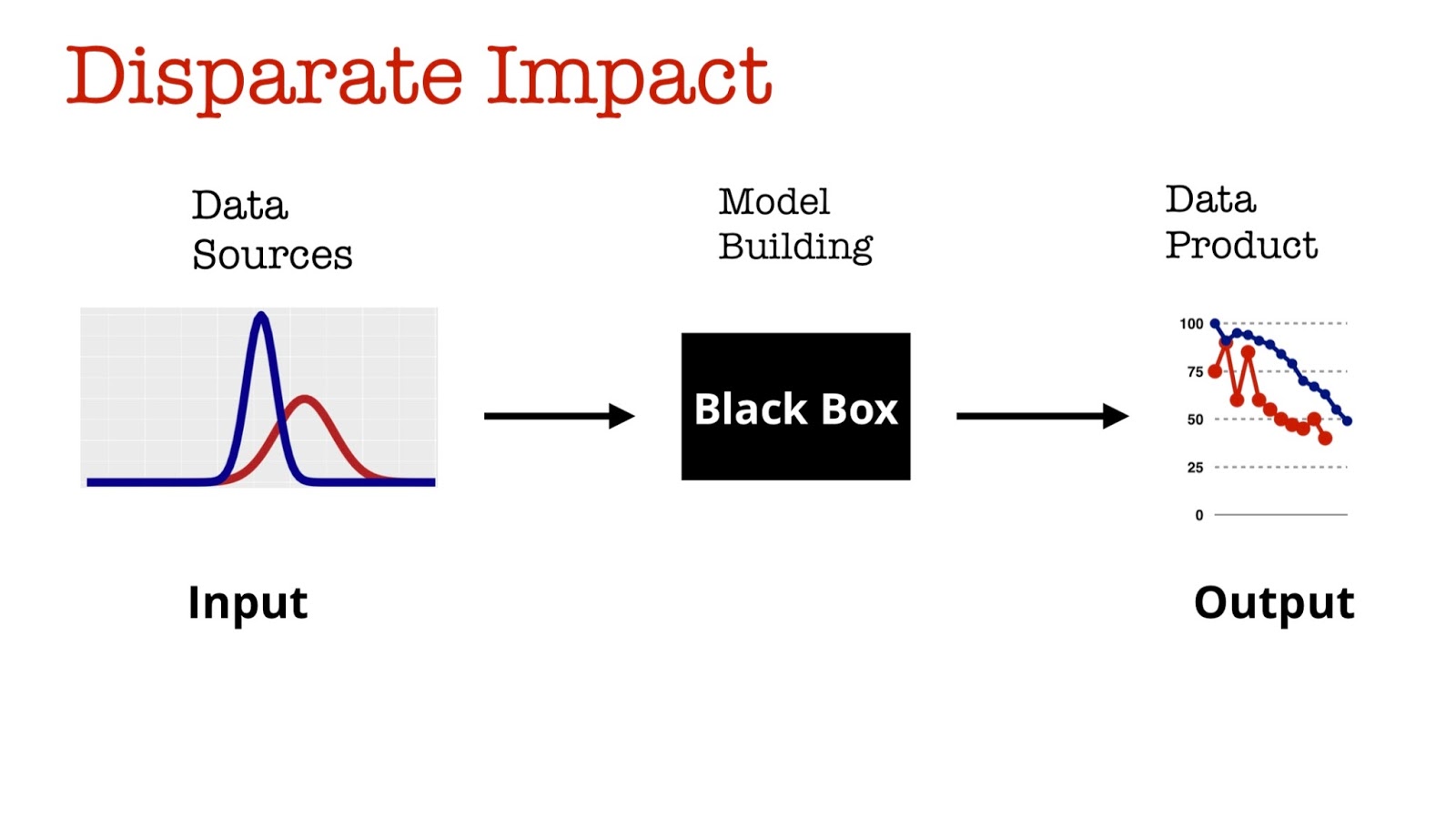
In 2014, a group of researchers offered a data renormalization method to remove disparate impact:

Another example has to do with error: once we are satisfied with a certain error rate, aren’t we done and ready to deploy our model to production? Consider a scenario where you have a machine learning model used in health care: in the course of model building, your training data for millenials (in red) is quite large compared to the number of labeled examples from senior citizens (in blue). Since accuracy tends to be correlated with the size of your training set, chances are the error rate for senior citizens will be higher than for millenials.
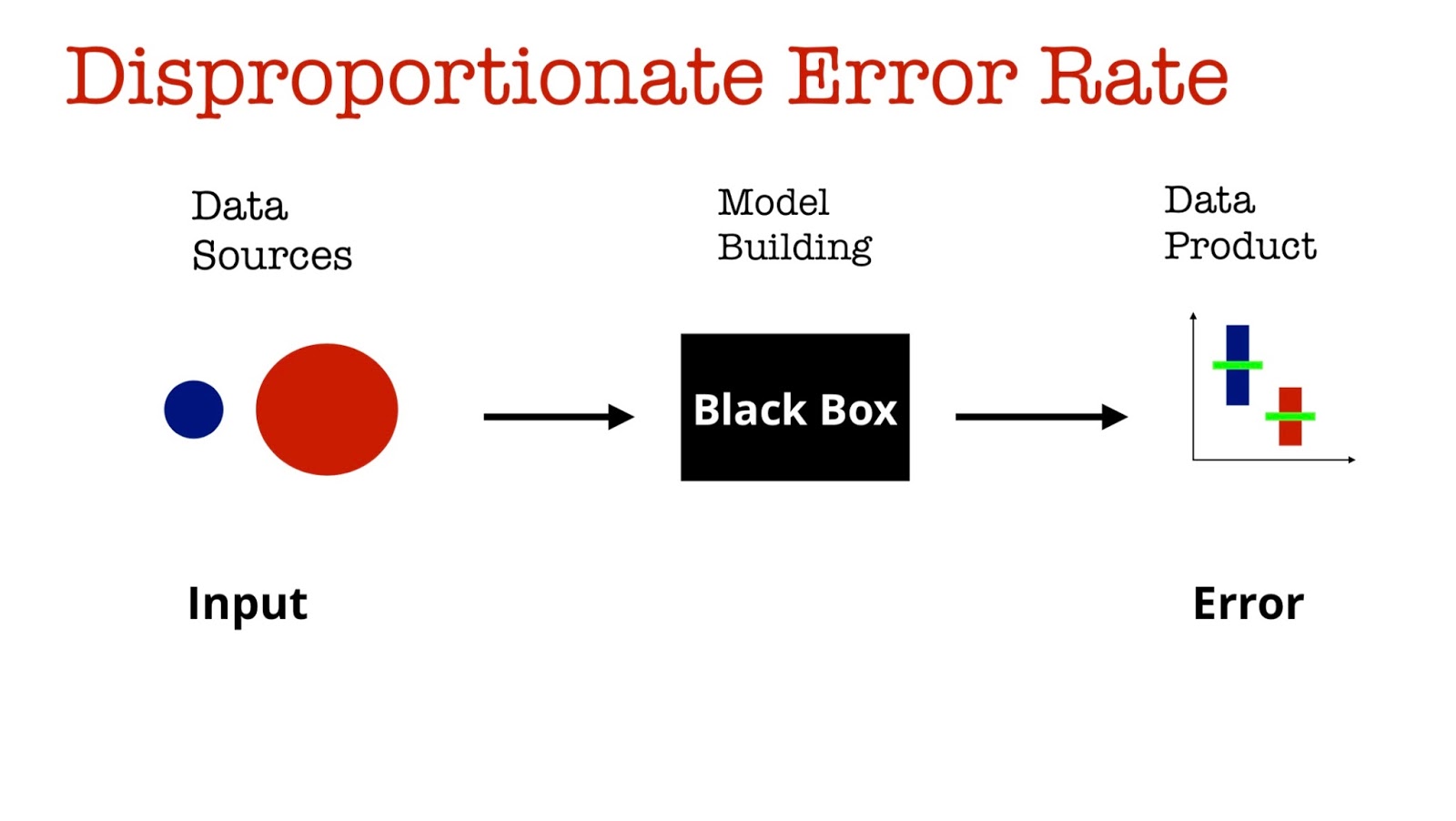
For situations like this, a group of researchers introduced a concept, called “equal opportunity”, that can help alleviate disproportionate error rates and ensure the “true positive rate” for the two groups are similar. See their paper and accompanying interactive visualization.
So, at least for association “bugs” we have a few items that we should be checking for:
 Slide by Ben Lorica,
Slide by Ben Lorica, Discovering unwarranted associations will require tools to augment our data scientists and machine learning engineers. Sometimes the output space for your models will be too big for manual review and inspection. In 2015, Google Photo included an automatic image tagging utility that failed badly in certain situations. Google was strongly criticized for it (and rightfully so), but to their credit, they stepped in and came up with a fix in a timely fashion. This is an example where the output space—the space of possible “tags”—is large enough that things can easily go undetected. Machine learning engineers could have used QA tools that surface possible problems they can review manually, before deploying this model in production.

The original checklist for deploying and managing models in production contains items that are related to some of the issues I’ve been discussing:
- Monitoring models: In many cases model performance degrades necessitating periodic retraining. Besides monitoring ML or business metrics, it’s also reasonable to include tools that can monitor for unwarranted associations that may start creeping up.
- Mission-critical apps: As machine learning gets deployed in critical situations, the bar for deployment will get higher. Model reproducibility and error estimates will be needed.
- Security and privacy: Models that are fair and unbiased may come under attack and start behaving unpredictably. Users and regulators will also start demanding that models be able to adhere to strict privacy protections.
Let’s take the checklist for machine learning engineers and add some first steps to guard against bias.

This is for a single model (or a single ensemble of models). As we look ahead, we know that companies will start building machine learning into many products, tools, and business processes. In reality, machine learning engineers will be responsible for many, many models in production:

How do we help our machine learning engineers identify models that are breaking bad? Note that this is similar to a problem that we’ve encountered before. Companies have been building tools (observability platforms) to help them monitor web pages and web services, and some of the bigger companies have been monitoring many time series. In 2013, I wrote about the tools Twitter was using at the time to monitor hundreds of millions of time series.

As companies deploy hundreds, thousands, and millions of machine learning models, we need tools to augment our data scientists and machine learning engineers. We will need to use machine learning to monitor machine learning! At the end of the day, your staff of experts will still need to look through issues that arise, but they will need at least some automated tools to help them handle the volume of models in production.

{kind=link}
In 2018, we need to treat model fairness, transparency, and explainability much more seriously. The machine learning research community is engaged in these issues, and they are starting to offer suggestions for how detect problems and how to alleviate problems that arise. Because companies are beginning to roll out machine learning in many settings, we need to build machine learning tools to augment our teams of data scientists and machine learning engineers. We need our human staff to remain at the frontlines, but we need to give them tools to cope with the coming tsunami of models in production.
[A version of this post appears on the O’Reilly Radar.]
Related content:
Update (2018-04-02): A recent article on Wired has a summary of recent efforts by developers to make their facial recognition products more fair.