

Large language models ease the development of useful chatbots
By Kenn So and Ben Lorica.
With the release of GPT-3 in 2020, users got to see what it might be like to interact with a computer that understands short text prompts and can generate responses and longer passages at a humanlike level. Many technologists hailed it as a great step forward. Some researchers pointed out failure modes and biases exhibited by GPT-3. Journalists rushed to find scandals.
But what’s been missing in recent media coverage is real progress in applying large language models and related technologies to practical applications. One of the authors (Kenn So) is seeing more startups with real value and business traction. Copy.ai, which uses GPT-3 to write marketing copy, grew recurring revenue from zero to $2.4M with over 300,000 marketers from companies like eBay and Nestle in just one year. Customer service chatbots played an important role during the pandemic as call centers had to scale back due to the pandemic.
While GPT-3 was the largest language model when it was released, there are now models that are 10x bigger than it. More importantly GPT inspired many research groups to create their own large language models (LLM). Private and public companies, academic research labs, and open source communities have created LLMs in multiple languages.
GPT-3 and other LLMs have huge implications for conversational assistants (chatbots). In this article, we dive into recent advances in technologies, the core chatbot components, venture activity, and recent trends & predictions.
Why now?
The resurgence in interest in chatbots has been fueled both by academic advances and by real-world adoption. NLP has seen rapid development since the BERT transformer model was introduced in 2018. First introduced in 2019, SuperGLUE is a set of benchmark tasks designed to pose a more rigorous test of language understanding. As we write this post, three different teams from Baidu, Google and Microsoft have surpassed human baselines on the SuperGLUE NLP tasks.
LLM creation continues unabated: just seven months after OpenAI released the 175 billion-parameter GPT-3 model in June 2020, Google released the 1.6 trillion-parameter Switch model. Microsoft and Nvidia recently partnered to develop MT-NLG, a large and powerful monolithic transformer model with 530 billion parameters.
Startups and open source communities have been quickly turning NLP research into tools and libraries for developers. Rasa and Botpress are among the most popular software frameworks for developing chatbots. Symbl.ai provides enterprise-level APIs that can just be plugged in to transcribe audio and analyze text. Hugging Face is a very popular open-source project that brings together the latest NLP models and makes them accessible to non-NLP experts.
These developments have made it easier to build useful chatbots that users find engaging to interact with. While we typically think of Google Assistant and Amazon Alexa as symbols of conversational AI, the use cases are much more varied. Salesforce has seen a 700% increase in how many times users talk to its Einstein bots. Gartner predicts that by 2022, 70% of customer interactions will involve chatbots. The pandemic has only accelerated the adoption because people are forced to interact virtually. From 2018 to 2020, chatbot deployments have increased from 20% of organizations to 40%. As a result, the conversational AI market is expected to grow by 34% CAGR to over $16B by the year 2024.
Continued progress in tools like transfer learning bode well for chatbot developers needing domain-specific models. Transfer learning lets developers use elements of a pre-trained model and reuse them in a new machine learning model. It involves applying knowledge gained from solving a source problem in a source domain, to new situations. Spark NLP co-creator, David Talby, notes: “Transfer learning is used in just about every project we deliver nowadays, since it enables training highly accurate models with far fewer labels than previously possible. This enables answering specific or custom questions much faster – and we’re now making this capability available directly to domain experts using easy to use, no-code tools.”
Looking ahead, a new class of tools have the potential to deliver chatbots that can be efficiently updated or expanded. Retrieval-based NLP are a class of models that “search” for information from a corpus to exhibit knowledge, while using the representational strength of language models. Researchers at Stanford recently developed retrieval-based NLP models that delivered impressive results on a variety of Q&A benchmarks.
Chatbot basics
Chatbots are software systems designed to simulate a human conversation by processing and generating language data via text or voice. There are two types of chatbots:
- Task-oriented: designed to solve problems in specific domains. Problem types fall broadly into two categories: information retrieval (e.g. Q&A) or automation (e.g. close the lights). Domains are varied from business settings to personal assistants in our phones.
- Open Domain: designed without a particular purpose other than to hold a conversation about anything. These so-called chit-chat bots are less common because chatbots are usually built with a particular purpose in mind.
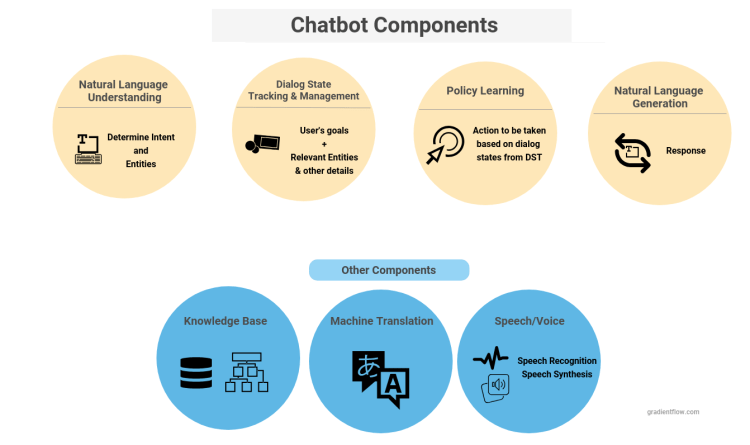
Understanding the key components of a chatbot can help set realistic expectations. When building a chatbot, or evaluating tools for building chatbots, or when you are projecting forward to gauge future capabilities of chatbots, it’s important that you have a high-level understanding of the progress or limitations in each of these key areas.
Chatbots have four primary components. They include NLU models to identify the intent and entities in conversations. There are also components for managing dialog by crafting what to ‘talk’ about next (i.e. dialog policy) and how to say it. There are secondary components that depend on the use case. A smart speaker would need the ability to recognize and synthesize voice. While Q&A bots would need a knowledge base to draw answers from.
Active venture space
With all the recent progress in models, tools, and frameworks, it’s not surprising the space has seen an influx of venture capital. $2.2B went into chatbots YTD, almost double the whole of 2020.

To help make sense of the fast-developing landscape, we mapped over 200 startups that have raised more than $2 million in the B2B conversational AI space. Below is a diagram of major subcategories and representative companies in each:

Closing thoughts
We close with a few observations and some near-term predictions:
-
- Most chatbots will continue to be task-specific. While open domain chatbots are fascinating, most chatbots we interact with will be task or domain-specific. Humans are generally organized into specialists, just like there are HR, IT, finance, etc. professionals. One area where open-domain chatbots might be useful, aside from being a virtual friend, is in game development. Game developers spend a lot of time crafting the personalities of each NPC (non-playable character). Conversational AI models can be tuned to reflect a diverse set of characters that make games enjoyable.
- As tools for Transfer Learning and Retrieval-based NLP become available, highly accurate, task-specific chatbots will become easier to build. Research into and the release of smaller language models should also further level the playing field for chatbot developers.
- Companies will need to assemble conversational AI teams. Much like how ML models have to be maintained, chatbots need to be maintained and improved regularly. One company we’ve talked to has a team of 12 just to maintain their chatbot. A traditional software or machine learning engineer won’t be skilled in all components of a chatbot. Maintenance will require a team of specialists including a conversational AI expert.
- End-to-end models will make chatbots more robust and simpler to maintain.
- Companies will end up using multiple large language models: Companies will use different LLMs for the different languages they need to support. Additionally, performance and deployment considerations could play a role in how large a model they should use for a specific application.
Kenn So is an investor at Shasta Ventures, an early-stage VC, and was previously a data scientist. Opinions expressed here are solely his own. He is actively looking for investment opportunities in the chatbot space.
Ben Lorica is co-chair of the Ray Summit, chair of the NLP Summit, and principal at Gradient Flow.
Related Content:
- “Data Quality Unpacked”
- “Taking Low-Code and No-Code Development to the Next Level”
- Alan Nichol: “Best practices for building conversational AI applications”
- Lauren Kunze: “How to build state-of-the-art chatbots”
- Matthew Honnibal: “Building open source developer tools for language applications”
- Connor Leahy: “Training and Sharing Large Language Models”
Subscribe to the Gradient Flow Newsletter: