

The Gap Between the Press Release and the Power Grid
Back in February, I wrote about what I called the “Data Center Rebellion,” the growing local resistance to the physical infrastructure behind AI. Since then, I have been asking tech people around the Bay Area how closely they are following the backlash. The answer is usually: they know it exists, but not much more than that. There is still a quiet assumption that most of these announced campuses will get built, plugged in, and brought online more or less on schedule. I am much less sure. What looked like a scattered set of zoning fights has hardened into something more organized, more politically potent, and more consequential for anyone trying to think clearly about AI infrastructure timelines. The opposition has gone from a speed bump to a genuine constraint.
Regularly reading? Consider becoming a paid supporter 🙏
The striking part is how broad the opposition has become. Polling suggests that resistance to local AI data centers is now a mainstream position, not a fringe one. And the “AI” label matters. Data centers have become a visible target for wider concerns about corporate power, electricity costs, water use, job displacement, surveillance, and who actually benefits from the buildout. The politics have also gone cross-ideological in ways that make this harder to dismiss. Environmental justice advocates, rural conservatives worried about local control, and labor groups anxious about automation are all finding common cause at the zoning board.
The Local Backlash Gets Smarter
The objections are practical and increasingly specific. Communities are worried about water in dry regions, electricity demand on strained grids, air pollution from backup power, the constant hum of cooling systems, farmland conversion, tax breaks, and the small number of permanent jobs these projects often create. The industry tends to lead with billion-dollar investment figures. Residents tend to ask a simpler question: what do we give up, and what do we actually get?

The tactics have matured too. This is no longer just online frustration or a few angry public meetings. Residents are using moratoriums, zoning challenges, lawsuits, ballot measures, protests, water-rights filings, and elections. What makes the backlash more durable is the trust problem. Shell companies, project code names, NDAs, fast-tracked approvals, and vague end-user disclosures make communities feel boxed out. Once that trust is gone, even reasonable technical claims start to sound like sales material.
Microsoft’s recent pledge to stop requesting NDAs is a useful illustration here. It’s notable precisely because it signals how widespread the practice has become. When a company feels compelled to make that kind of pledge, it’s an admission that the old playbook has become a liability.

Announced Capacity Is Not Real Capacity
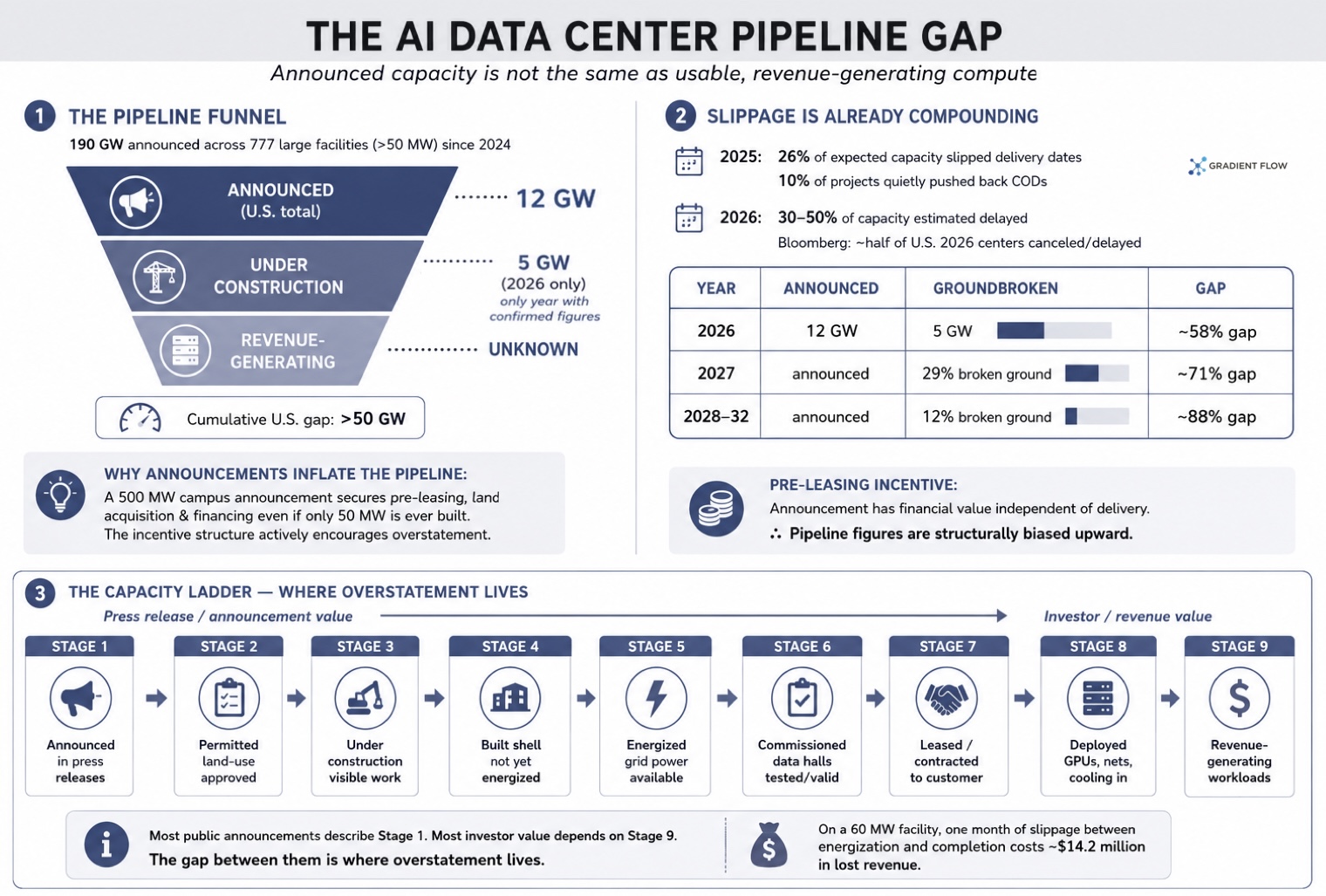
Local opposition gets much of the attention, but it is only one constraint. Even if a project clears the political process, it still has to get power, transformers, electrical equipment, GPUs, memory, networking gear, cooling systems, utility approvals, and enough skilled construction capacity. In many markets, the bottleneck has shifted from “can you get the chips?” to “can you get the megawatts?” A site can have land, permits, and a glossy announcement and still sit idle because the electrical infrastructure is not ready.
That’s why the gap between announced capacity and capacity under construction matters so much. Of the roughly 12 GW of U.S. data center capacity announced for 2026, only about 5 GW is under active construction. That ratio gets worse, not better, for later years. The industry’s pipeline looks enormous in press releases and investor decks, but only a fraction appears to be moving toward actual completion on the promised timeline. The word “capacity” can mean too many things: land under option, a permitted site, a building shell, reserved power, an energized hall, installed racks, or revenue-generating compute. Those are not minor distinctions. They are the difference between a story the market wants to hear and an asset that can actually serve AI workloads.

{kind=link}
The Trust Deficit Becomes an Execution Risk
The industry is responding, but mostly at the edges. Some developers are revising site plans, changing cooling designs, offering community benefits, making renewable-energy commitments, or becoming more selective about where they build. But they do not fully answer the harder questions: who pays for grid upgrades, who gets the water, who absorbs the noise and pollution, and who has the right to say no?
What concerns me is the financial exposure accumulating underneath all of this. More and more of this buildout is being funded through debt, long-term lease obligations, and capacity commitments made against a pipeline that is, in many cases, more announced than actually under construction. The hard question is whether the math works even if the projects do get built. Hyperscalers are spending as if AI infrastructure will unlock a very large new revenue pool. Maybe it will. But if capital spending keeps rising faster than revenue, the industry may discover that “demand” and “attractive return” are not the same thing. Either AI generates much more revenue than analysts currently expect, or some planned spending gets pushed out, scaled back, or canceled. That second outcome might not look like a crash. It could look like delayed campuses, slower GPU orders, tougher financing terms, and more “rephasing” language on earnings calls.

This is why I would not treat local opposition as a side story. The compute demand behind AI is not going away. That does not mean every project deserves a rubber stamp. It means the industry has to get much better at earning trust and building capacity that communities, utilities, and investors can actually live with. If AI infrastructure spending is helping support the broader economy, then a serious pause becomes a macro risk, not just an AI story. A slowdown isn’t even the worst version of this. It is an AI economy where compute becomes scarce, expensive, and concentrated in the hands of the few companies and customers that can afford it. That would be a bad outcome for everyone who wants AI to become broadly useful, not just broadly hyped.

- The MANIAC. I know this is a 2023 book, but it feels even more worth reading now. As AI reshapes computing, research, and mathematics, this portrait of John von Neumann made me wonder what one of history’s great mathematical minds would make of the machines we’ve built. This is historical & biographical fiction at its best 💯
- Steve Jobs in Exile: The Untold Story of NeXT. I had a couple of professor friends who were devoted NeXT users, and this helped me understand why that little black cube inspired such loyalty. This is a sharp, readable look at Jobs’ wilderness years, and how what looked like a detour ended up shaping the Mac, the iPhone, and the tools we use every day.
- Inside the Box: How Constraints Make Us Better. I liked this book because its core idea feels especially relevant to AI right now. DeepSeek and other Chinese model builders are a good reminder that constraints do not always slow innovation down, sometimes they force teams to get sharper, scrappier, and more creative.