

OpenAI and Anthropic are going public while still capturing much of the money spent on foundation-model usage. But deployment patterns are starting to tell a more complicated story. Companies are building hybrid model portfolios, using proprietary models where convenience, support, and frontier capability matter, while turning to open-weights models where cost, privacy, customization, and deployment control matter more. As teams get better at operating multiple models, the single-vendor AI stack will look less like the default and more like a transitional phase.
Enjoying this newsletter? Consider becoming a paid supporter 🙏
What Open Weights Give You And What They Do Not
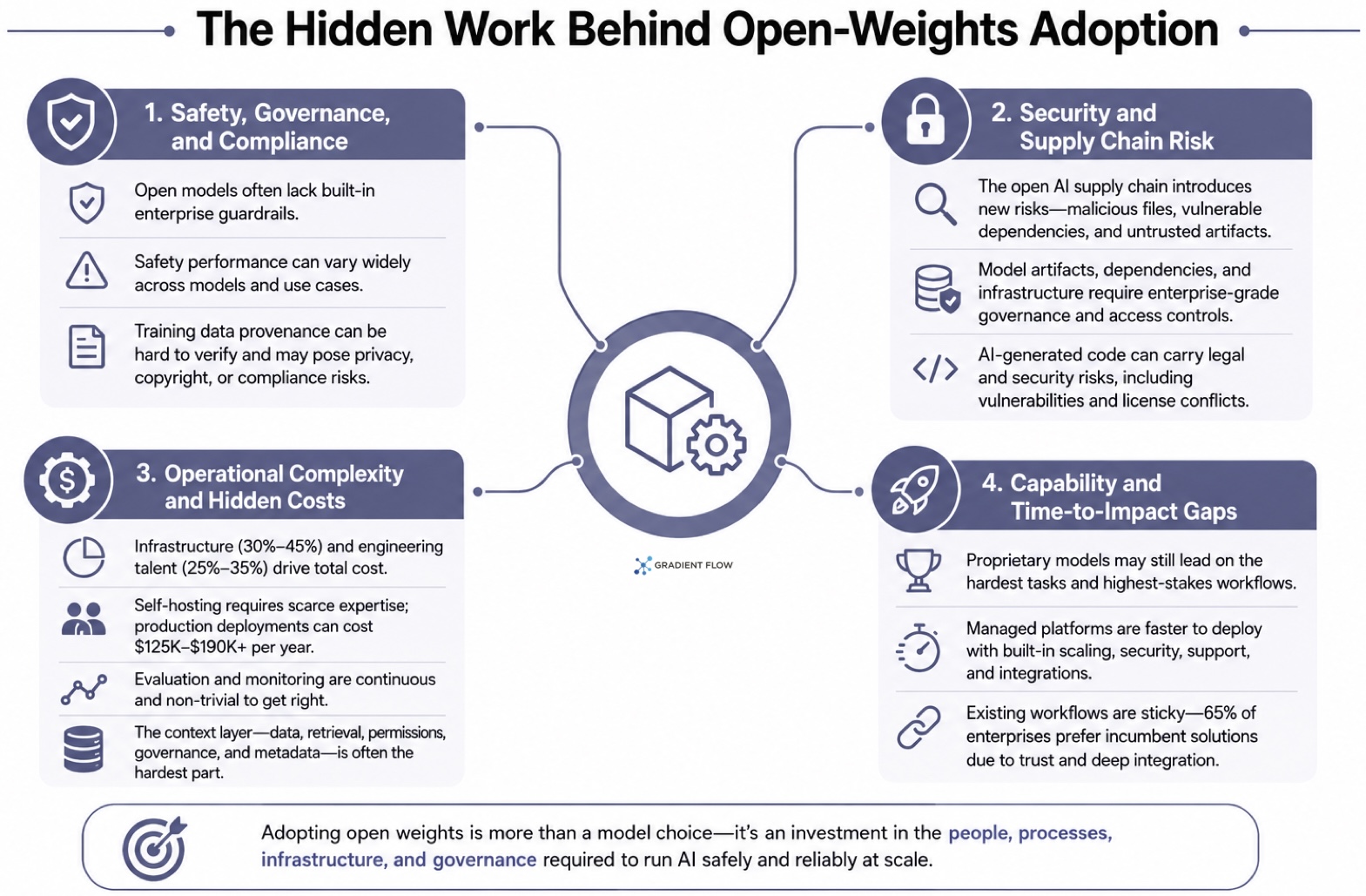
The economics are hard to ignore. In an earlier piece, I argued that the CFO has become the CTO, the Chief Token Officer. That framing applies directly here. Proprietary APIs are still useful for prototyping, broad assistants, and difficult reasoning tasks. But once a workflow becomes stable and high volume, token-based pricing starts to feel like a tax on scale. Open-weights models can cut unit costs sharply for repeatable work such as document processing, classification, extraction, internal search, customer support, and summarization. The savings are not automatic. Infrastructure and engineering costs have to be absorbed first. But for organizations running millions of daily inferences, the case can become compelling much sooner than many executives expected.

{kind=link}
The appeal is not just lower cost. Open-weights models give enterprises more control over where data goes, how models are adapted, and which version is running in production. That matters for banks, insurers, healthcare organizations, manufacturers, software companies, and any business handling sensitive records, proprietary code, contracts, customer conversations, or regulated data. A model that runs in a private cloud, on-premises environment, or approved regional infrastructure can be easier to govern than one accessed only through a third-party endpoint. With open-weights models, enterprises can select a model version, test it, approve it, and keep running it. This is valuable for regulated or high-stakes systems where silent behavior changes create audit and compliance problems. Fine-tuning and post-training lets teams adjust model behavior without retraining the whole system. RAG, or retrieval-augmented generation, lets a model consult a curated internal knowledge base before answering. Together, these patterns allow smaller models to perform well on company-specific workflows.
The barriers are just as practical. Switching to open weights is not like swapping an API key. Proprietary platforms package hosted endpoints, scaling, documentation, security features, enterprise support, and contractual accountability. Open-weights models shift more of that burden to the buyer. Teams need GPU planning, model serving, inference optimization, monitoring, evaluation, logging, access control, fallback paths, and cost tracking. The total cost of ownership is easy to underestimate because the API bill disappears, but the operational work does not. In some organizations, infrastructure and specialized engineering talent can become the dominant cost. Open weights can improve economics, but only for teams mature enough to run them well.

{kind=link}
The governance issues are even harder to wave away. Proprietary platforms usually include safety layers and enterprise risk support. Open-weights models often require companies to build those controls themselves. Input/output guardrails, red-team testing, incident response, secure artifact management, and model provenance all become first-class engineering concerns. Tools such as Heretic show why this matters. Safety guardrails can be stripped from open-weights models quickly, which raises obvious compliance and misuse risks. Legal teams also have real work to do. “Open-weight” does not mean unrestricted. Licenses may limit commercial use, redistribution, scale, geography, or specific capabilities. And when these models are used for code generation, companies need processes for scanning outputs for vulnerabilities and license conflicts.
The New Enterprise Model Stack
The next phase is not open versus closed. It is workload-specific model selection. A routine classification task can go to a smaller open-weights model. A sensitive internal search workflow can run inside private infrastructure. A difficult reasoning problem can be escalated to a proprietary frontier model. This is the real meaning of hybrid model portfolios. The architecture is no longer about picking one best model. It is about building a routing and governance layer that can evaluate requests, choose the right model, monitor cost and quality, and replace models when needed. I already see this in my own coding workflow. My O2 toolkit, using opencode and OpenRouter, is useful precisely because different models are better for different jobs.

{kind=link}
This hybrid approach becomes even more critical as we move toward agentic workflows. When you build autonomous agents that continuously run loops, call tools, and handle background tasks, your token consumption scales dramatically. If you run these entire multi-step workflows on premium proprietary endpoints, your monthly API bill will explode. Instead, a smarter architecture uses smaller, local open-weights models to handle the routine, repetitive steps in an agent’s loop, while escalating only the high-stakes decisions or complex reasoning tasks to closed frontier models. This setup also keeps the agent’s sensitive tool integrations and internal system commands within your own secure network rather than routing them through external APIs. The catch is that agents make the control layer harder to build. Every action needs to be logged, auditable, and ideally reversible, and most teams deploying agents have not built that infrastructure yet.
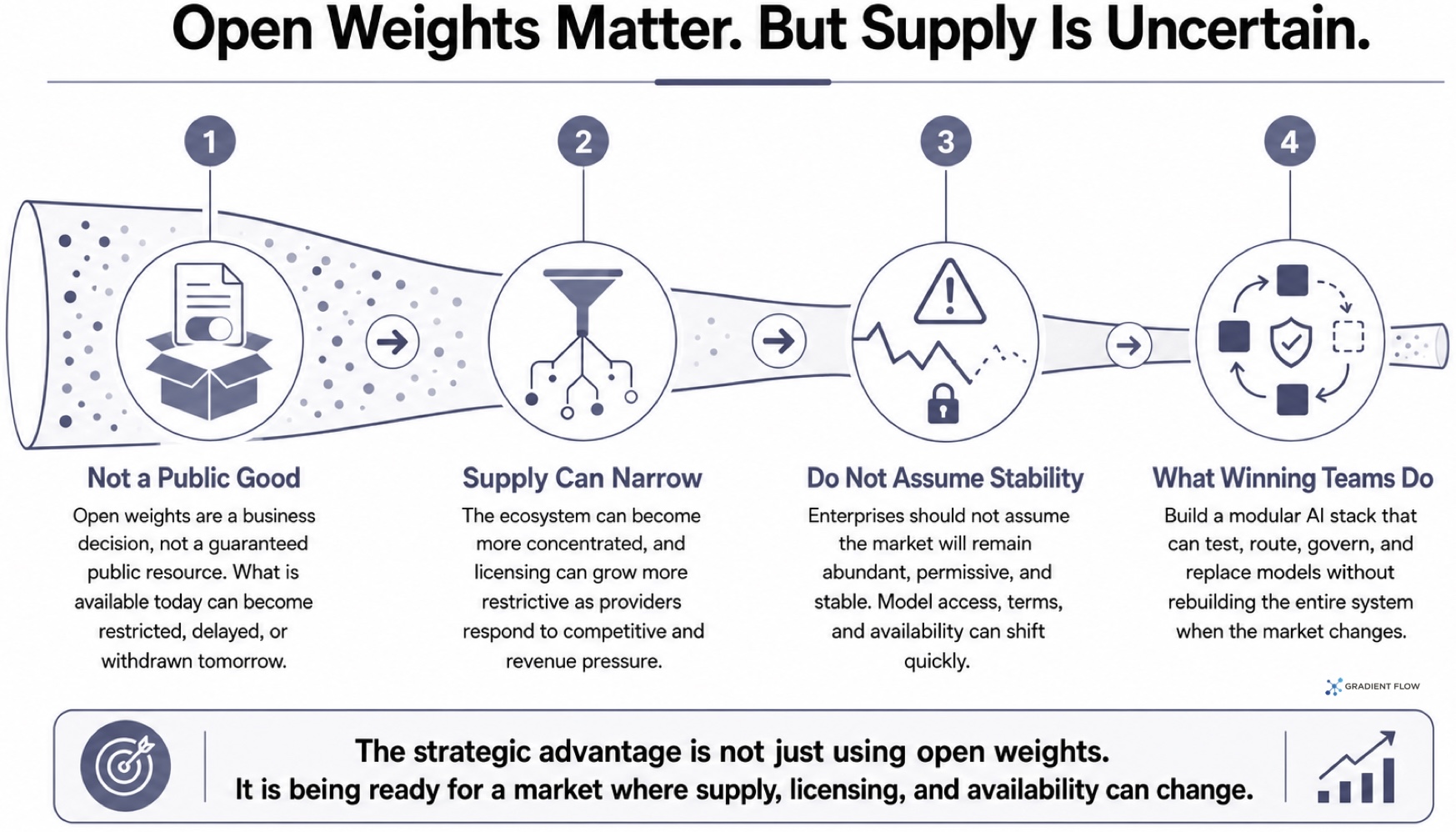
Open-weights are a business decision, and business decisions can be reversed.
This shift in workload routing has uncomfortable implications for OpenAI and Anthropic as they move toward IPOs. Their revenues may continue to grow quickly, but pricing power will face pressure from below. If open-weights models are good enough for a larger share of routine inference, enterprises will become more selective about when they pay premium API prices. They will still pay for frontier reasoning, managed compliance, uptime, enterprise support, convenience, and strong guardrails. But they will be less willing to send every summarization, extraction, routing, tagging, retrieval, and support workflow to the most expensive model. Revenue can grow while the price umbrella weakens.

{kind=link}
The biggest uncertainty is supply. Open weights are not a guaranteed public good. They are a business decision, and business decisions can be reversed. OpenAI demonstrated that years ago. Meta now appears less committed to Llama as an open ecosystem than many expected. At the same time, the open-weights landscape has become more concentrated among Chinese labs, and even that supply is narrowing as some providers move toward closed or more restricted licensing under revenue pressure. This is the part of the story that deserves more attention. Enterprises should absolutely take open weights seriously, but they should not assume the ecosystem will remain abundant, permissive, and stable. The winning teams will be the ones that can test, route, govern, and replace models without rebuilding their AI stack every time the market shifts.