

Why Your AI Agents Fail in Production (And How to Actually Test Them)
In a previous post, I argued that deploying autonomous AI agents reliably is not primarily a model problem. It is an environment problem. The gap between a capable foundation model and a production-ready system is bridged by harness engineering: the discipline of building structured workflows, validation loops, and governance mechanisms around the model rather than inside it. The central argument was that organizations that treat the surrounding environment as the primary engineering target outperform those that chase better models, and that this principle applies across every domain where agents handle complex, consequential work.
That argument raises an immediate practical question: how do you actually know whether an agent is ready for that work? Most existing evaluations still measure narrow, low-friction tasks in controlled or synthetic environments. They can tell you whether a model produces a plausible answer or completes a neat subtask, but they reveal far less about whether an agent can stay coherent across a long workflow, adapt when something breaks, and finish a job that actually runs. Many benchmarks were simple enough that top models were already approaching perfect scores, leaving no meaningful signal about which systems could handle real work and which could not.
Value this newsletter? Consider becoming a paid supporter 🙏
What production usually demands is sustained execution under friction: long chains of interdependent actions, genuine error recovery, and deep domain knowledge applied to messy, open-ended objectives. That is a fundamentally different test than anything most benchmarks were designed to measure. The commercial stakes behind closing that gap are no longer abstract. Terminal-based coding agents alone are already generating billions in revenue, which means accurate measurement of what these systems can and cannot do in realistic conditions has moved from research interest to commercial necessity for anyone building, deploying, or investing in AI agent products.
Measuring the Agent, Not the Demo
Some of the most capable autonomous agents in production today are still concentrated in coding and software engineering. That makes sense. The terminal is one of the few environments where success criteria are clear and feedback arrives immediately. An agent cannot hide behind a fluent answer when a build fails, a dependency breaks, or a command returns the wrong output. It has to keep working until the job is done.
Terminal Bench was built around that reality. It places agents inside real terminal environments loaded with the files, packages, and system configurations needed for the task. Each problem includes an instruction, a verification script, and a reference solution. What gets measured is not whether the agent followed a preferred sequence of steps, but whether it reached a machine-checkable result. There is no partial credit for looking competent. The output either works or it does not.

The significance is not just that Terminal Bench is harder. It is harder in ways that matter. Previous benchmarks often measured narrow command-line skills, relied on synthetic environments, or used tasks so short that they revealed little about sustained execution. Terminal Bench instead asks whether an agent can manage long sequences of dependent actions, recover from real error messages, and apply domain knowledge to open-ended work. Its rigor also comes from the curation. Every task in Terminal Bench is manually reviewed to reduce broken tests, underspecified instructions, and loopholes that let agents game the evaluation. The early results show why that level of manual verification matters. Frontier agents still fail more than a third of the tasks, and smaller models perform much worse. For anyone building, deploying, or investing in agents, that makes Terminal Bench less a leaderboard curiosity than a practical instrument for separating systems that look capable from systems that can actually finish difficult work.
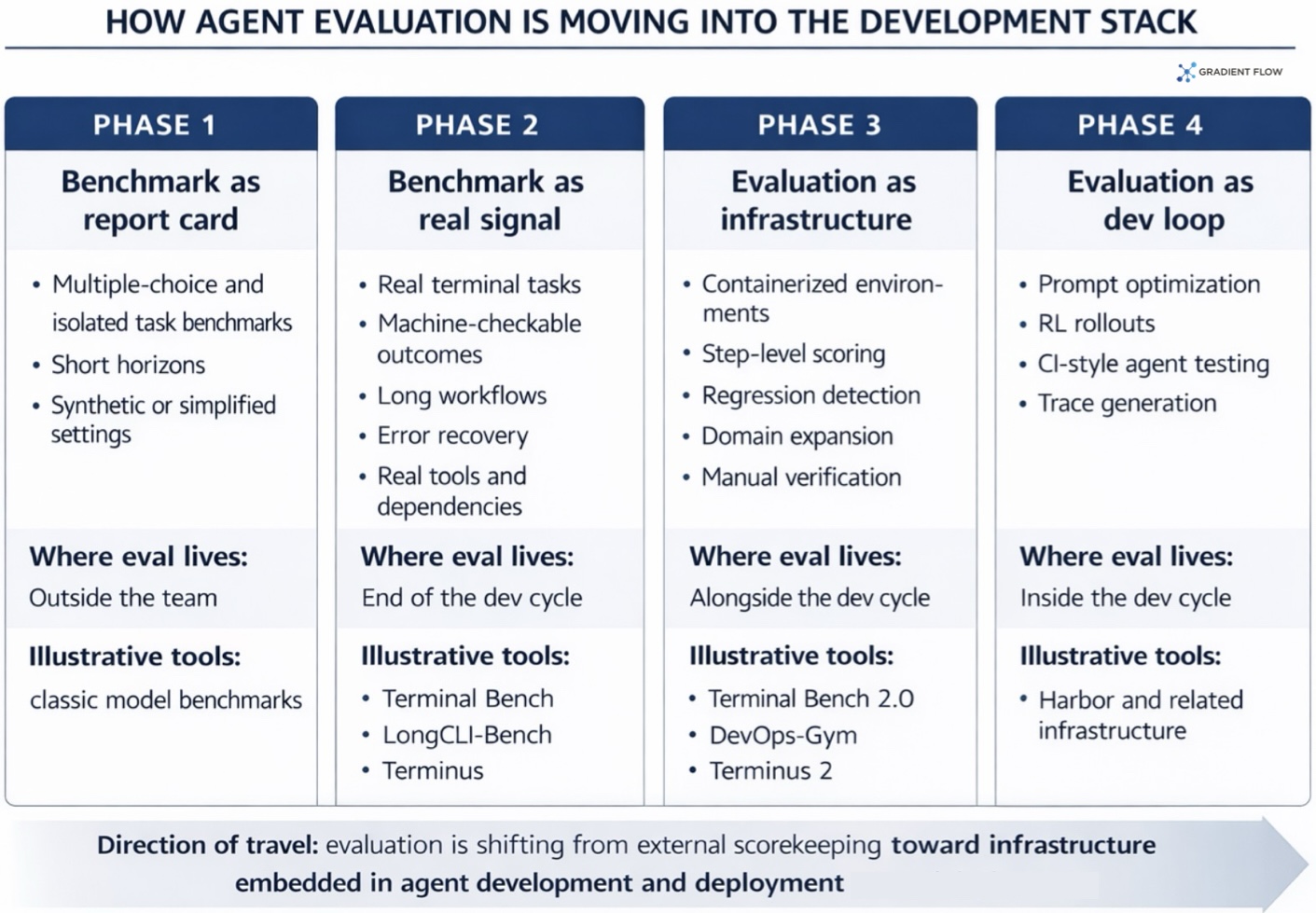
Evaluation is no longer a report card at the end of a cycle. It belongs directly inside the development stack.
The Emerging Infrastructure for Real Agent Evaluation
Terminal Bench has not developed in isolation. A small but important set of related efforts is now building on the same premise that agent evaluation should look more like real technical work and less like a polished demo. LongCLI-Bench pushes this further by focusing on longer command line tasks and by adding step-level scoring, so an agent is penalized not only for failing to finish the job but also for breaking something that previously worked. That is a meaningful advance for anyone building production agents, because regression is often the real failure mode. DevOps-Gym pushes the boundary further into real-world software operations, evaluating agents on their ability to configure builds, monitor systems, and resolve live issues instead of just completing isolated terminal prompts.

{kind=link}
The ecosystem is also expanding into the infrastructure needed to train and compare terminal agents at scale. TermiGen addresses one of the clearest bottlenecks exposed by Terminal Bench, namely the cost of hand-building realistic environments and trajectories for training and evaluation. Terminus and Terminus 2 provide reference implementations for how a terminal agent can interact with a live shell over many steps, which makes them useful both as engineering baselines and as cleaner testbeds for comparing models. And the appearance of fine-tuned terminal-focused systems such as Reptile, LiteCoder-Terminal, and TerminalAgent suggests that terminal competence is now being treated as a distinct capability worth training for directly. Taken together, these developments make Terminal Bench look less like a standalone benchmark and more like the anchor for a broader effort to measure and improve agents that have to do real work under real constraints.
What Comes Next, and What It Means Outside the Terminal
The near-term roadmap for Terminal Bench is really about keeping the benchmark informative. As agents improve, benchmarks only stay useful if they keep stretching the best systems, which means adding harder tasks, expanding domain coverage, and refreshing the suite before leaderboard movement stops meaning anything. Just as important, the Terminal Bench team is making an explicit argument that manual verification is not optional. Their experience showed that confirming task correctness, closing loopholes, and fully specifying success conditions takes substantial human effort, and that cost rises with task complexity.
The infrastructure supporting Terminal-Bench has become more valuable than the benchmark itself. Harbor serves as the expanded framework that allows developers to go beyond basic testing, giving them the tools to optimize AI prompts, run trial-and-error learning, and perform automated quality checks on their agents. That is a meaningful shift. Evaluation is no longer a report card at the end of a development cycle. It is moving into the development stack, not sitting outside it. The ecosystem growing around Terminal Bench is what that shift looks like in practice.
The real leverage comes from the surrounding system, not just the model.
For companies building agents outside coding, this is probably the clearest near-term lesson. The winning approach is unlikely to be full autonomy across messy, high-stakes workflows. It is more likely to be structured human-agent collaboration inside tightly engineered environments. That fits the larger argument in my previous post. The real leverage comes from the surrounding system, not just the model. Terminal Bench sharpens that claim by showing that even in a domain where feedback is fast and success is machine-checkable, reliable autonomous performance remains limited. In domains where mistakes are subtler and more consequential, companies will need even more harness, more evaluation, and more deliberate handoffs between automated execution and human judgment.
Quantum Computing Supply Chains

{kind=link}

- The Laws of Thought: The Quest for a Mathematical Theory of the Mind. AI is starting to shape the economy, the job market, and national security. That’s why I think more people should understand the concepts in this highly readable book.
- Mutiny: The Rise and Revolt of the College-Educated Working Class. This book struck me as a preview of something bigger. The college grads making lattes and running Apple Store demos are already living the gap between what their degrees promised and what the economy delivers. With AI moving into knowledge work, that gap may widen for many more people.
- London Falling. One of my favorite writers delivers again here. I came away feeling like London is not just the setting but almost a character in its own right, with all its glamour, fraud, and seedy underbelly baked into the story.