

Insights and trends that will help you navigate the data management landscape.
By Assaf Araki and Ben Lorica.
Given our focus on data, analytics, and machine learning, we regularly hear pitches from startups building new data management solutions. Data management is a broad area that includes solutions for different workloads, data types, and use cases. We still encounter startup teams pursuing less-optimal ideas, including:
- Data Management Systems with On-Premise focus. There are still a few early-stage data management startups that target the on-premises market, where there are well-established and entrenched enterprise software vendors that are difficult to unseat. Considering that enterprises are quickly adopting cloud computing technologies, startups should instead focus on cloud-native solutions to accelerate their customer acquisition and learning rates.
- One-size fits all systems. While researchers and experts have long pointed out that there are significant differences in performance between specialized systems and general DBMSs, we still meet early-stage startups focused on building a single platform designed to replace systems that power both transactional and analytical applications.
- Integrated platforms. In the early days of big data (Hadoop, etc.), teams of data and platform engineers had to install software, manually configure clusters, and constantly manage and tune multiple, complex software systems. While there are now many more tools that simplify and automate many of these tasks, we still hear pitches from teams who focus primarily on integrating and consolidating different software components. Tools have evolved to the point where startups will have to demonstrate value beyond simply integrating disparate software frameworks.
Putting aside these poorly focused examples, we remain excited about the space: data management is a vibrant area that features some of the largest unicorns today. We list reasons and key trends that lie behind our bullishness, and detail things that data teams and platform architects should keep in mind as they evaluate data management solutions in the months ahead.

The Cloud DB market is growing faster than the overall DB market
Expert Market Research recently predicted that the global DBMS market would grow at an annual rate (CAGR) of 12.4% to $125.6 Billion by 2026. In comparison, Valuates Reports estimates that the cloud DBMS market will reach USD $68.7 Billion by 2026, at a compound annual growth rate of 38.2%. This is in line with the findings from our Data Engineering Survey, where most respondents indicated plans to adopt a cloud database over the next 12-24 months.
There are a growing number of DBaaS across all workloads and data types
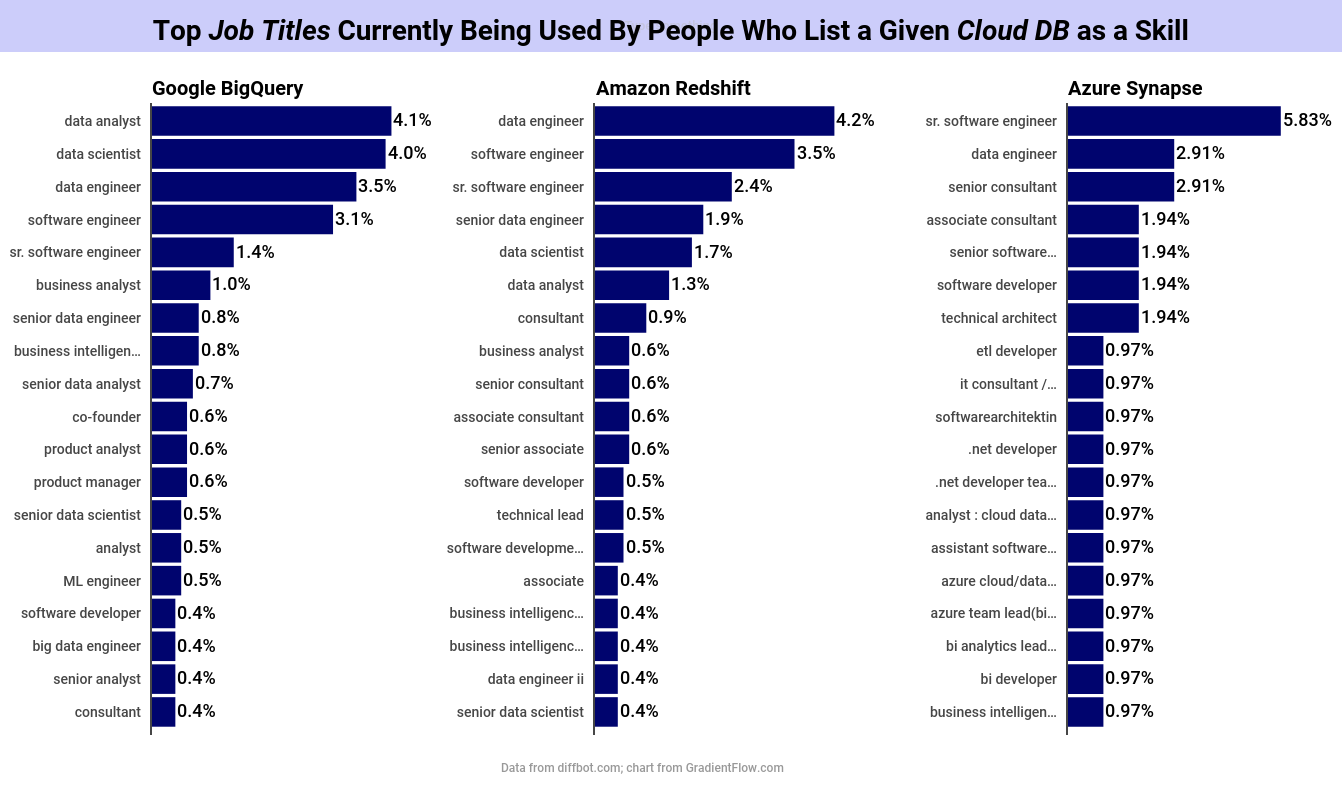
With the rise of cloud warehouses and lakehouses, teams needing database as a service (DBaaS) solutions for BI and analytics can choose from a variety of platforms including Google BigQuery, Databricks, Amazon Redshift, Snowflake, and Azure Synapse.
A similar shift to the cloud has occurred for operational databases (e.g., MongoDB Atlas, Datastax AstraDB, Redis, CockroachDB, to name a few). A recent study from Stack Overflow revealed that traffic to discussion pages pertaining to Amazon Relational Database Service (RDS) increased 40% year-over-year. Traffic to Stack Overflow pages that cover Amazon Aurora – a cloud-native database with MySQL and PostgreSQL-compatibility – grew 200% year-over-year. Specialized systems such as graph databases, time-series databases, and vector databases, are also rolling out DBaaS offerings.
When it comes to broad metrics of usage, open source has surpassed commercial systems
DB-Engines ranks database management systems using a range of factors and data sources including search engine indexes, Google Trends, job postings, discussion boards, and social and professional networks. In early 2021, open source surpassed commercial database management systems in the DB-Engines comparison index. Among the ten top systems in DB-Engines, the majority are open-source with PostgreSQL, Redis, Mongodb, and Elasticsearch among the fastest growing.

Another interesting metric is the number of active mentions on Reddit (specifically, r/Database). Once again open source systems dominate the top 10 list.

Finally, one sure sign of a system’s popularity is the size of its ecosystem and the popularity of its interfaces. By most accounts, Postgres has become the “API” for operational databases and many other systems are adopting its interfaces.
The emergence of serverless query services on object stores
In our recent Data Engineering Survey, we found AWS Athena and Google BigQuery to be among the most popular services. Athena and BigQuery provide interactive query services that use standard SQL to analyze data stored in object stores. There are a growing number of similar serverless options available. Companies that have rolled out serverless query services include Databricks (Serverless SQL), Rockset, MinIO (MC SQL), and Microsoft (Azure Data Lake Analytics).
The pull of modern data platforms will continue to get stronger
In our recent Trends in Data and AI report, we noted that Modern Data Platforms (MDP) – cloud data warehouses and lakehouses – have spawned a vibrant ecosystem of startups and tool providers. Many data startups are integrating with modern data platforms and some specifically target companies that use MDPs. The ecosystem of tools that integrate with MDPs includes tools for data discovery, data quality, data integration, and more (this ecosystem is referred to as the “modern data stack”). Like other platforms that have significant traction, MDPs find themselves in the midst of a virtuous cycle: MDPs have many users; this makes them attractive to tool builders and application developers; as the ecosystem of tools and applications surrounding MDPs becomes stronger, even more users opt for MDPs; and this cycle repeats.
There are more options for accessing databases
Databases were originally monoliths consisting of tightly integrated components: a storage engine, a computation engine, and domain-specific language. Each database engine had its own SQL extensions – Oracle had PL/SQL while Microsoft had T-SQL – and users who adopted a specific extension found themselves quickly locked into a computation engine.
More recently, cloud-native ETL and ELT tools (Matillion, dbt, Rivery, Fivetran, Airbyte) and low-code tools (Tableau, Looker) provide a single API and act as translators to a variety of databases and computation engines. Decoupling API from compute means users need to learn only one API to run pipelines and programs on new computation engines or a new database.
The next phase is the rise of intermediate representation layers that add another level of flexibility. Tools like Modin, Substrait, and Weld make databases accessible to users already familiar with Python, SQL, etc. For example, users who are familiar with and fluent in tools like Pandas can use many different database systems without missing a beat.

What’s Missing: Startup Opportunities
We opened this post with a list of systems that a startup should not be focused on, what follows are a few items that developers and aspiring entrepreneurs might want to consider.
Autonomous OLTP DBaaS
There aren’t enough database administrators and database experts: per a recent report, IT staff grew only by 1% in the last two years. A typical enterprise organization has hundreds, even thousands of DBMS instances. Only a fraction are monitored and supported by human database administrators (DBA).
The increased usage of cloud DBaaS has made the staffing shortage even more pronounced. On the one hand, modern data platforms (cloud warehouses and lakehouses) have made it easier for companies to launch and manage data management systems for analytics and machine learning applications.
On the other hand, OLTP DBaaS still demand attention and specialized talent. Developers do not want to provision and maintain databases, and CTOs don’t want to hire consulting companies to optimize and manage OLTP databases. The good news is that we’re beginning to see projects and systems that use machine learning to optimize and manage databases. Solutions like OtterTune and Oracle AD aim to make database management systems autonomous and self-driving.
DBMS for Computer Vision
The rise of deep learning for computer vision has led to exponential growth in the use of visual data (images, video). Progress in data infrastructure has however lagged behind: most computer vision teams continue to build bespoke data management solutions and store images in flat files. With the growing importance of visual data, teams need database management systems that come with a storage engine, data representation, query compiler, query optimizer, and access to requisite domain-specific languages. This is an active area and some early building blocks and systems include TileDB, Scanner, ApertureData, and ActiveLoop.
Closing Thoughts
Companies who can collect and unlock data resources will be able to innovate and operate more efficiently than their peers. Looking beyond BI and towards more sophisticated applications, the growing interest in tools for data-centric AI places the spotlight squarely on DataOps and data management systems. We hope the insights and trends we’ve described will help you navigate the data management landscape. In our next post we plan to release a similar list for machine learning.
Assaf Araki is an investment manager at Intel Capital. His contributions to this post are his personal opinion and do not represent the opinion of the Intel Corporation. #IamIntel
Ben Lorica helps organize the Data+AI Summit and the Ray Summit, is co-chair of the NLP Summit, and principal at Gradient Flow. He is an advisor to Databricks and other startups.
Related content: Other posts by Assaf Araki and Ben Lorica.
- Machine Learning Trends You Need to Know
- Get Ready For Confidential Computing
- An Enterprise Software Roadmap for Sky Computing
- What is DataOps?
- The Growing Importance of Metadata Management Systems
- AI and Automation meet BI
- Demystifying AI Infrastructure
- Software 2.0 takes shape
FREE Report:

[Featured Image: Top Job Titles Currently Being Used By People Who List A Given System as a Skill on their Profile.]
{kind=link}