

How and why the best companies are adopting Graph Visual Analytics, Graph AI, and Graph Neural Networks.
By Leo Meyerovich and Ben Lorica.
[A version of this post originally appeared on the Graphistry blog.]
In this post, we highlight the current state of Graph Intelligence, a new technology category around new tools and techniques for gathering insights around relationships in data from sources like SQL tables and logs. We introduce the term Graph Intelligence to refer to the ability to produce insights over structured entities, values, known relationships, and inferred relationships. The primary methods for Graph Intelligence are graph visualization and analytics (Graph VA) and graph machine learning models (Graph AI). Non-obvious to many, Graph Intelligence projects often forgo using the technology categories of Graph Databases (Graph DBs) and Knowledge Graphs: they solve different problems so we defer much of their discussion for future articles.
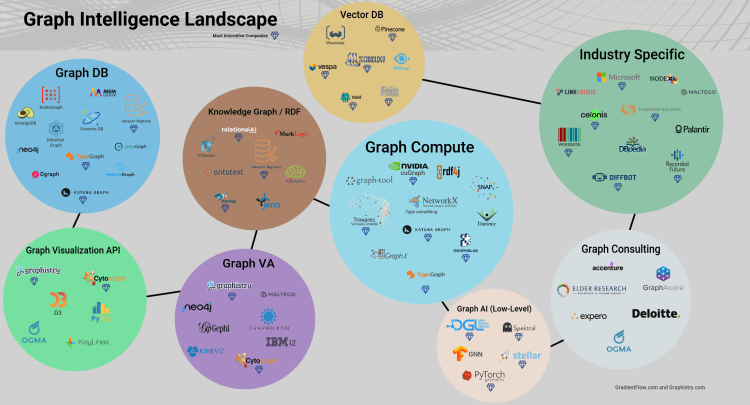
A key and recent catalyst for the fast-moving Graph Intelligence ecosystem (Figure 5) is that companies increasingly already have the data and infrastructure necessary to get started. Most teams do not use Graph DBs, but they do have structured data, especially in relational databases: such structured data can often be usefully analyzed for graph insights (Figure 1). As we will discuss, tools that convert structured data into graphs for Graph Intelligence are now common and easy to use.
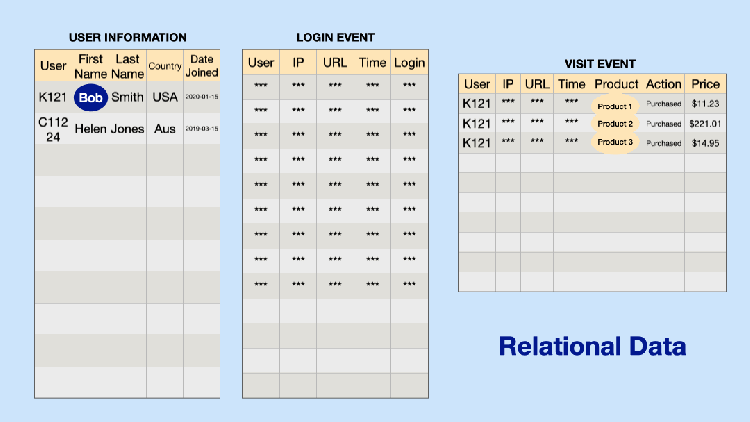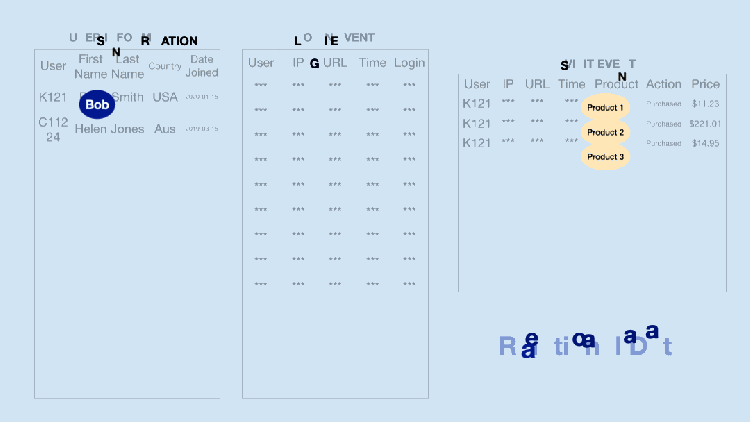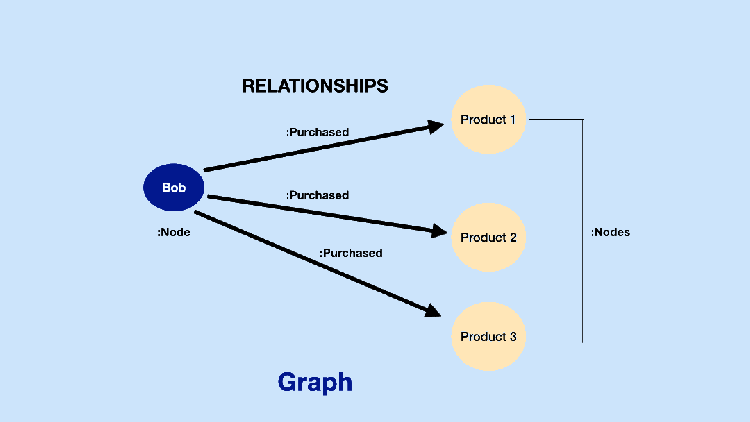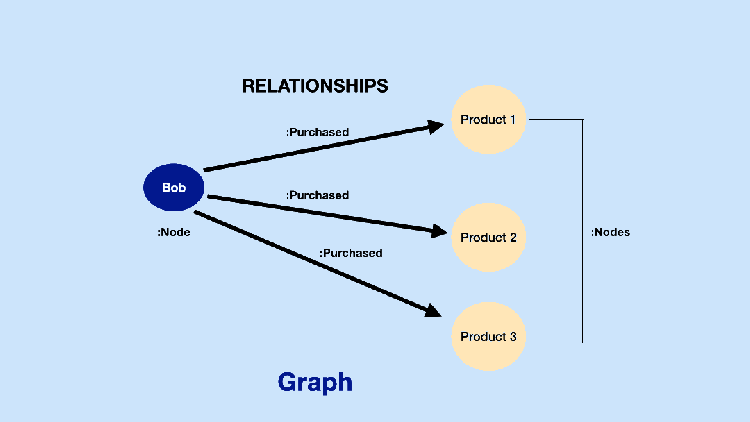
At a time when AI is going through hypergrowth, Graph AI is a growing proportion of all AI. An increasing number of areas and applications, such as recommenders and neural networks, that previously weren’t associated with graphs, are beginning to use Graph Intelligence approaches. Companies like Pinterest, Uber, eBay, and Google have reported significant improvements in core areas like recommendations, fraud detection, and forecasting models after incorporating Graph Neural Networks (GNNs). Graph Neural Networks leverage graph structure for better results or to answer graph questions. We collected core industry uses by prominent companies in Figure 2 below.
Companies like Pinterest, Uber, and Google have reported significant improvements in recommendations, fraud detection, and forecasting models after incorporating GNNs.
Graph VA unlocks information such as the most significant entities, groups, patterns, journeys, and behaviors: traditional visualization and analytics tools generally fail to distill these. We use the term Graph VA to differentiate from Graph AI in two ways. First, advanced graph visualization and analytics, such as visually exploring a network diagram, are more easily used by analysts. Second, while Graph VA insights might be from GNNs, non-GNN analytics techniques are still often more effective. Examples include listing top clusters or searching for specific patterns.
For many teams, graph insights are useful but only intermittently; in these cases, the result is that integrating Graph VA with existing visualization and analytics tools can be sufficient. At the same time, companies like Goldman Sachs, Uber, Airbnb, Linkedin, Siemens, and Amazon identified graph-oriented questions across their business units important enough to invest in building custom Graph VA solutions. Thus vendors across industries are increasingly embedding shallow Graph VA capabilities into their products.

Investing in Graph Intelligence
Many organizations that are now transitioning to Graph AI first got comfortable with Graph Intelligence by investing in Graph VA. The data remains the same for Graph AI, but the methods used to derive value have become increasingly sophisticated. Leading examples include Microsoft’s, Amazon’s, and PayPal’s security and fraud teams, who began by investigating connections across customer activities.
Graph Intelligence will be a sizable percentage of the $299B AI market.
Market activity in graph technologies suggests Graph Intelligence is a top growth area. A recent study of the adjacent Graph DB category forecasts, “The global graph database market size to grow from USD 1.9 billion in 2021 to USD 5.1 billion by 2026.” The relevant part for Graph Intelligence is that the key driving growth factors for the Graph DB category are the “need to incorporate real-time big data mining with visualization of results, increasing adoption for AI-based graph database tools and services to drive market, and growing demand for solutions that can process low-latency queries”. That means two of the three growth drivers for Graph DBs are for aiding Graph Intelligence. Focusing on the intelligence aspect, estimates of the global AI market predict AI growing from $29.86 billion in 2020 to $299.64 billion by 2026. That makes AI 60X bigger than the Graph DB market, and we identify Graph AI as a growing and increasingly top segment of AI overall.
Our analysis suggests Graph Intelligence has the potential to become a significantly larger and better funded field than Graph DBs and should be prioritized as a separate category for investment:
- The existing market devoted to mining structured data like events, logs, and transactions is established and much larger than the Graph DB market.
- Graph Intelligence both adds the ability to leverage complex relational data to make existing models more powerful, and introduces new kinds of insights. Our prediction is that Graph Intelligence will be a significant portion of the AI market, which is already large and undergoing hypergrowth.
Rapid growth in the need to glean actionable insights from company data for core functions should create a sense of urgency for companies to delve into Graph Intelligence approaches. This is especially true for graph methods enabling automation, democratization, and performance. Organizations that start now will be in a better position to employ new tools, like GNNs, that are coming from the research community at a fast rate. We give tips on how to approach this journey in the Getting Started section.
Why now
There are several reasons why Graph Intelligence is poised to grow in importance in the near future. First, companies are increasingly ready: as we noted above, operational data and event data are ubiquitous, and companies already have systems in place to collect and store it. Likewise, as we will discuss, compute is now also more accessible than ever.
Secondly, companies and researchers are reporting Graph AI to be a measurably superior AI technique for their use cases. Teams are demonstrating that graphs can provide better answers to behavioral questions as well as provide the basis for smarter fraud detection and recommendation systems (see Figure 2). The growing variety of best-of-class results in AI benchmarks and adoption by top industry teams has caught the attention of many data teams we have worked with recently. The AI research community is increasingly focused on GNNs, with Figure 3 showing how almost half of last year’s top new AI research papers explicitly mention GNNs. We expect that Graph AI tools will become more readily accessible to industry over the next 2 years.

The rise of Graph Intelligence is being enabled by compute becoming much more accessible. Fast compute is required for maintaining interactivity in analyst experiences and for techniques like GNNs. Notably, all the major cloud providers have a variety of GPU instances, and all major phones and browsers have supported GPUs for years.
Graph Intelligence architectures are converging to patterns that largely complement modern data platforms.
Related to compute becoming accessible is the rise of modern managed data platforms. They reduce implementation friction for Graph Intelligence. When we first started working on big data several years ago, many companies manually built their own graph data platforms using components like Hadoop/Spark, Elasticsearch, Airflow/Nifi, and Neo4j. Today, modern cloud data warehouses, data lakehouses, and graph databases feature convenient managed services with bundled software.
A key property of modern data platforms for adopting Graph Intelligence is how they separate compute from storage. This has enabled graph tools to work directly over modern storage systems. New graph tools such as graph visualizers, machine learning libraries, NLP knowledge graphs, and Python/R packages convert structured data to graphs on-the-fly in the compute tier. This means that graph tools can now interoperate with non-graph storage technologies holding non-graph format data. This compute-tier approach has been further advanced by data lakehouses and compute libraries standardizing on interchange through IO-optimized open formats like Apache Parquet and Apache Arrow. The resulting compute-tier graph pipelines run fast at gigabyte and even petabyte scales without rearchitecting the data stack. For example, adding Graph VA to lakehouse dashboards can now take minutes. Graph AI especially benefits from modern data platforms because AI workflows frequently perform bulk data actions around import/export, wrangling, and enrichments.
Combined, companies can now reuse storage infrastructure investments to feed fast and simple graph compute pipelines running at the compute tier. The result is teams regularly report Graph Intelligence initiatives that exceed historically challenging scales and timelines.
The Graph Intelligence Stack
Graph Intelligence solutions are converging to a new architectural pattern that complements modern data platforms. Surprising to many, the majority of Graph Intelligence use cases do not require a Graph DB because they can instead use the compute tier to manipulate graphs on-the-fly. Consider the striking example from the Chinese e-commerce giant Meituan. In a recent presentation, the company described using a graph database to store a knowledge graph for one use case but noted that none of their thirty GNN deployments across a variety of departments use a graph database. Meituan also noted that they do not plan to add a graph database to their GNN use cases. Teams like Meituan instead work at the compute tier by converting arbitrary data to graph representations on-the-fly for consumption by best-of-class Graph AI libraries. There’s been more than $500M invested in Graph DBs in the past few years with Graph AI as one of the motivators. We see the value in Graph DBs, but the specific scenario of adding alternative databases to architect a Graph Intelligence solution deserves consideration of if, how, and when.
You don’t need a graph database: none of Meituan’s 30 GNNs use one.
Notably, Vector Databases may fill gaps in Graph Intelligence architectures. Graph AI typically represents entities, relationships, and results as wide vectors (e.g., embeddings). These vector representations are key to how AI tools understand data, quickly answer relationship questions like “which entities and events are similar to this one”. Popular SQL and graph databases still have limited or no native support for vector data operations. The result is that we are seeing AI teams experimenting with Vector Databases explicitly designed for AI training and serving.
Graph DBs have unique strengths as well, such as OLTP read/write performance on multi-hop queries that are high-throughput & large-scale. However, when planning a Graph Intelligence use case, Graph DBs may be an expensive misdirection, especially initially. This can be due to the value provided being orthogonal to a team’s Graph Intelligence needs. Modern data platforms are already simple and scalable via graph compute packages, and GraphDBs present impedance mismatches with modern Graph Intelligence workflows.

Getting Started
Graph VA provides a natural starting point for many companies looking to get started with graphs, especially for teams not already deep into neural networks or not immediately interested in programming one.
One historic path to Graph VA is to begin with a graph database. Graph DBs make certain Graph VA queries easier to express and faster to execute, and they come with tools (UI, query language, plug-ins, modules) designed to help users ease into graphs and “graph thinking”. However, these tools are more aimed at database administrators and developers and not for direct use by analysts. Even user-friendly Graph DBs like Neo4j explicitly recommend partners for Graph VA and Graph AI. Architecturally, Graph DB benefits come at the cost of a separate system that duplicates and complicates investments into modern data platforms and graph compute tiers. So while a GraphDB may be the right choice in the long-term, they may cause an expensive false-start problem specifically for Graph VA and Graph AI projects.
Our recommendation for most companies starting out is to jump right in.
Instead, our typical recommendation for most companies starting out is to jump right in with Graph VA first before embarking on a Graph DB project. As we noted, modern data platforms enable teams to quickly evaluate whether a compute-tier graph approach matches their initial and future requirements. Likewise, this approach has another advantage in that your team might find it simpler to directly connect your existing SQL/noSQL database into visual Graph Intelligence platforms like Graphistry and Kineviz. The result is delivering graph initiatives can become faster and less risky. We recommend that teams focus on rapid delivery of initial business value and de-risk a subsequent (or parallel) initiative to adopt Graph DBs.
Companies getting started with Graph Intelligence or transitioning from Graph VA to Graph AI will find a robust tools landscape. Figure 5 illustrates the major players today, but we expect this space to rapidly mature as Graph Intelligence becomes mainstream.
To get you started in your Graph VA journey, the Graphistry team built several free tools:
- A no-code tool that automatically turns a CSV file into a graph
- An open source toolkit and open source library that turn tables into interactive visual graphs in 1-2 lines of code, and works with data science notebooks and Python dashboards
- An upcoming PowerBI integration that works with your existing BI deployment
For graph compute, new technologies like the CPU-optimized xGT (Trovares) and GPU-optimized RAPIDS cuGraph connect into modern data stacks, scale without requiring a database, and interoperate with Graph VA and Graph AI tools. Graph DB vendors support in-DB compute through their query languages, include algorithm libraries like Neo4j GDS and TigerGraph GSL, and pair well with Graph VA partner tools. As discussed, graph databases typically suffer from impedance mismatches with best-of-class Graph AI pipelines. Amazon Neptune graph database team has been making public strides to bridge that gap using Neptune ML and integrating components like scalable GPU GNN libraries, orchestration, and managed services.
Graph AI is currently aimed more at skilled neural network practitioners, with popular libraries including DGL, PyTorch Geometric, and StellarGraph. They are all low-level with different strengths.
Closing thoughts
It’s just a matter of time until graphs become a standard method to analyze data for operational insights. Figure 5 shows that tools are now in place for most companies to get started. As we’ve noted throughout this post, companies already have the necessary data and infrastructure to benefit from Graph Intelligence approaches.
Companies can adopt Graph Intelligence in stages. We recommend beginning with Graph VA to introduce graph thinking to your company. If you are already doing machine learning using structured data (e.g. recommendation systems or fraud detectors), you might be able to significantly improve your results by using GNNs. But note that for now, GNNs still take dedicated resources to get started.
Graph Intelligence will emerge as the approach that produces the best results for many use cases within companies that continue to seek more efficient and effective ways to analyze their growing streams of data. Early adopters of Graph Intelligence will have an edge in their markets, and will be able to benefit more rapidly from new tools like GNNs coming out of the research community.
To continue your journey into the growing Graph Intelligence ecosystem, try out the free tools above and signup to get Graphistry’s monthly Graph the Planet update of community news and launches delivered to your inbox.
Thank you for feedback from Michele Catasta (Google X), Alex Morrise (Graphistry), Prasanna Srikhanta, and Hannes Stark (MIT)
Update (2022-03-10): Leo and I discuss this post (as well as recent updates) in a recent episode of The Data Exchange podcast.
Leo Meyerovich is founder and CEO of Graphistry, a startup that builds visual graph intelligence tools for big or complex data. Graphistry partners as the Graph Intelligence tier for many of the companies in the landscape diagram.
Ben Lorica is a Principal at Gradient Flow. He is an advisor to Graphistry and other startups.
Subscribe to the Gradient Flow Newsletter: